 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyses of Multi-collection Corpora via Compound Topic Modeling
Paper and Code



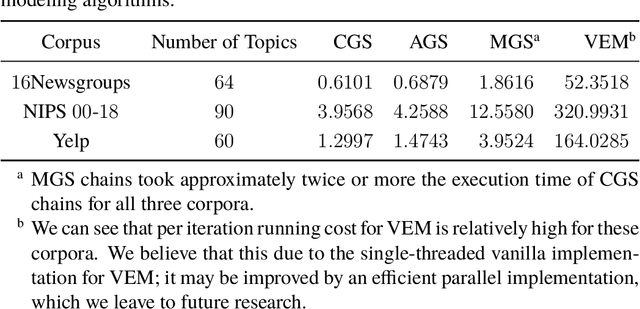
As electronically stored data grow in daily life, obtaining novel and relevant information becomes challenging in text mining. Thus people have sought statistical methods based on term frequency, matrix algebra, or topic modeling for text mining. Popular topic models have centered on one single text collection, which is deficient for comparative text analyses. We consider a setting where one can partition the corpus into subcollections. Each subcollection shares a common set of topics, but there exists relative variation in topic proportions among collections. Including any prior knowledge about the corpus (e.g. organization structure), we propose the compound latent Dirichlet allocation (cLDA) model, improving on previous work, encouraging generalizability, and depending less on user-input parameters. To identify the parameters of interest in cLDA, we study Markov chain Monte Carlo (MCMC) and variational inference approaches extensively, and suggest an efficient MCMC method. We evaluate cLDA qualitatively and quantitatively using both synthetic and real-world corpora. The usability study on some real-world corpora illustrates the superiority of cLDA to explore the underlying topics automatically but also model their connections and variations across multiple collections.