 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogies minus analogy test: measuring regularities in word embeddings
Paper and Code
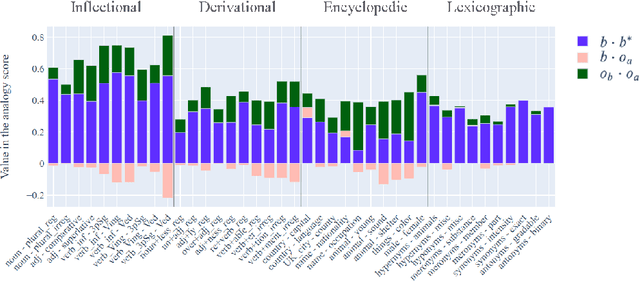

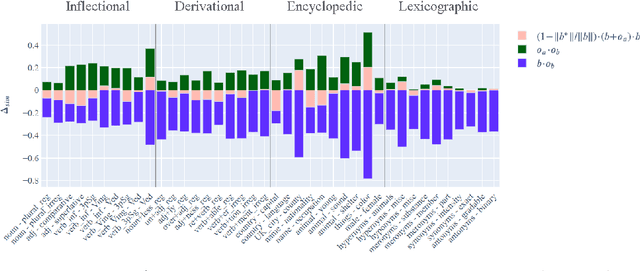

Vector space models of words have long been claimed to capture linguistic regularities as simple vector translations, but problems have been raised with this claim. We decompose and empirically analyze the classic arithmetic word analogy test, to motivate two new metrics that address the issues with the standard test, and which distinguish between class-wise offset concentration (similar directions between pairs of words drawn from different broad classes, such as France--London, China--Ottawa, ...) and pairing consistency (the existence of a regular transformation between correctly-matched pairs such as France:Paris::China:Beijing). We show that, while the standard analogy test is flawed, several popular word embeddings do nevertheless encode linguistic regularities.