 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn objective evaluation of the effects of recording conditions and speaker characteristics in multi-speaker deep neural speech synthesis
Paper and Code
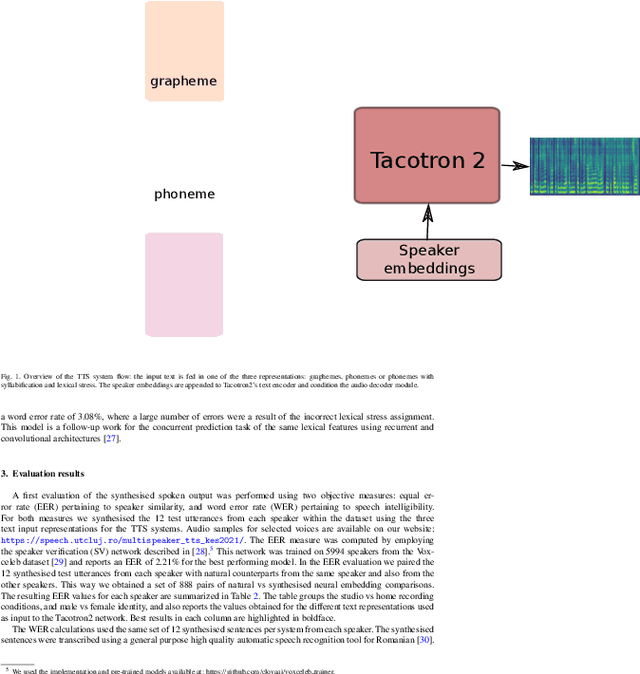
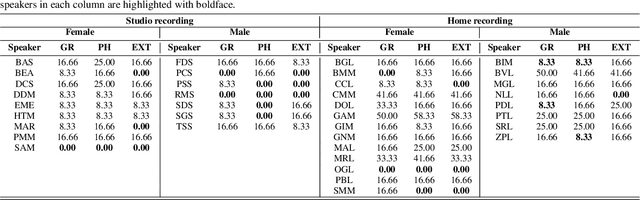
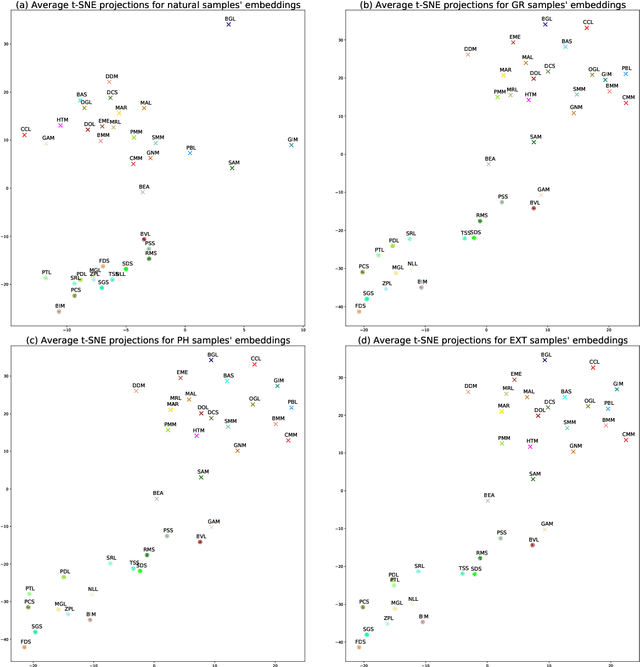
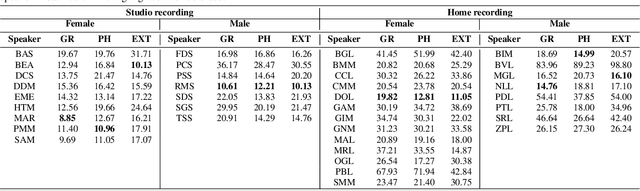
Multi-speaker spoken datasets enable the creation of text-to-speech synthesis (TTS) systems which can output several voice identities. The multi-speaker (MSPK) scenario also enables the use of fewer training samples per speaker. However, in the resulting acoustic model, not all speakers exhibit the same synthetic quality, and some of the voice identities cannot be used at all. In this paper we evaluate the influence of the recording conditions, speaker gender, and speaker particularities over the quality of the synthesised output of a deep neural TTS architecture, namely Tacotron2. The evaluation is possible due to the use of a large Romanian parallel spoken corpus containing over 81 hours of data. Within this setup, we also evaluate the influence of different types of text representations: orthographic, phonetic, and phonetic extended with syllable boundaries and lexical stress markings. We evaluate the results of the MSPK system using the objective measures of equal error rate (EER) and word error rate (WER), and also look into the distances between natural and synthesised t-SNE projections of the embeddings computed by an accurate speaker verification network. The results show that there is indeed a large correlation between the recording conditions and the speaker's synthetic voice quality. The speaker gender does not influence the output, and that extending the input text representation with syllable boundaries and lexical stress information does not equally enhance the generated audio across all speaker identities. The visualisation of the t-SNE projections of the natural and synthesised speaker embeddings show that the acoustic model shifts some of the speakers' neural representation, but not all of them. As a result, these speakers have lower performances of the output speech.