 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Isotropy Analysis in the Multilingual BERT Embedding Space
Paper and Code
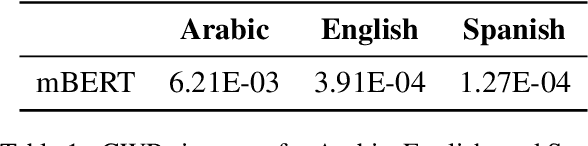



Several studies have explored various advantages of multilingual pre-trained models (e.g., multilingual BERT) in capturing shared linguistic knowledge. However, their limitations have not been paid enough attention. In this paper, we investigate the representation degeneration problem in multilingual contextual word representations (CWRs) of BERT and show that the embedding spaces of the selected languages suffer from anisotropy problem. Our experimental results demonstrate that, similarly to their monolingual counterparts, increasing the isotropy of multilingual embedding space can significantly improve its representation power and performance. Our analysis indicates that although the degenerated directions vary in different languages, they encode similar linguistic knowledge, suggesting a shared linguistic space among languages.