 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Algorithm of Robot Path Planning in Complex Environment Based on Double DQN
Paper and Code
Jul 23, 2021

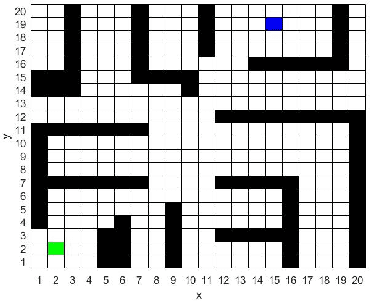
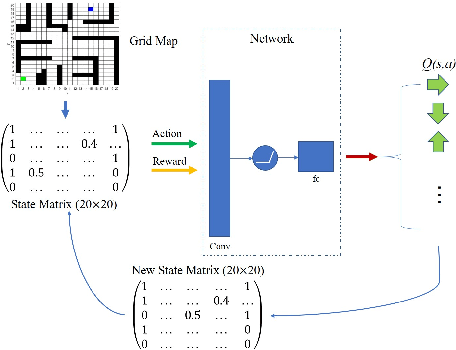
Deep Q Network (DQN) has several limitations when applied in planning a path in environment with a number of dilemmas according to our experiment. The reward function may be hard to model, and successful experience transitions are difficult to find in experience replay. In this context, this paper proposes an improved Double DQN (DDQN) to solve the problem by reference to A* and Rapidly-Exploring Random Tree (RRT). In order to achieve the rich experiments in experience replay, the initialization of robot in each training round is redefined based on RRT strategy. In addition, reward for the free positions is specially designed to accelerate the learning process according to the definition of position cost in A*. The simulation experimental results validate the efficiency of the improved DDQN, and robot could successfully learn the ability of obstacle avoidance and optimal path planning in which DQN or DDQN has no effect.