 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploration of Prompt Tuning on Generative Spoken Language Model for Speech Processing Tasks
Paper and Code


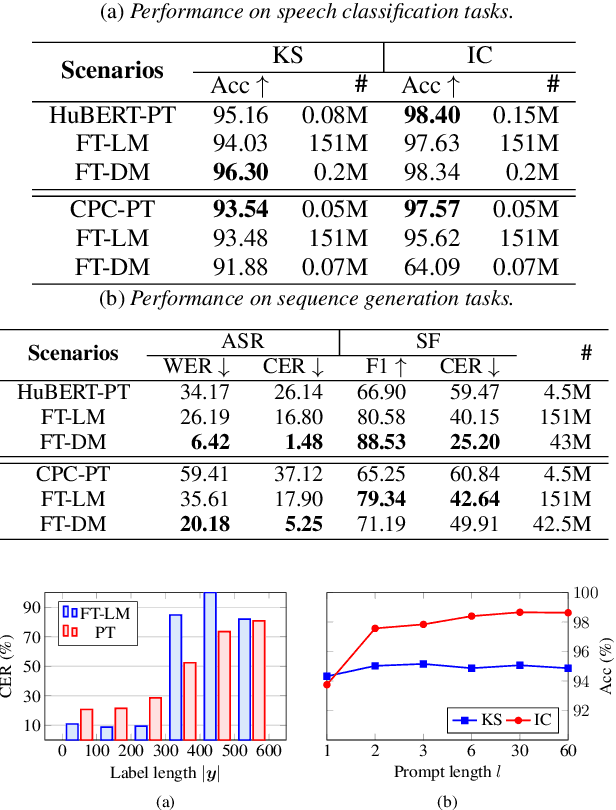

Speech representations learned from Self-supervised learning (SSL) models have been found beneficial for various speech processing tasks. However, utilizing SSL representations usually requires fine-tuning the pre-trained models or designing task-specific downstream models and loss functions, causing much memory usage and human labor. On the other hand, prompting in Natural Language Processing (NLP) is an efficient and widely used technique to leverage pre-trained language models (LMs). Nevertheless, such a paradigm is little studied in the speech community. We report in this paper the first exploration of the prompt tuning paradigm for speech processing tasks based on Generative Spoken Language Model (GSLM). Experiment results show that the prompt tuning technique achieves competitive performance in speech classification tasks with fewer trainable parameters than fine-tuning specialized downstream models. We further study the technique in challenging sequence generation tasks. Prompt tuning also demonstrates its potential, while the limitation and possible research directions are discussed in this paper.