 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Entropy-based Variable Feature Weighted Fuzzy k-Means Algorithm for High Dimensional Data
Paper and Code
Dec 24, 2019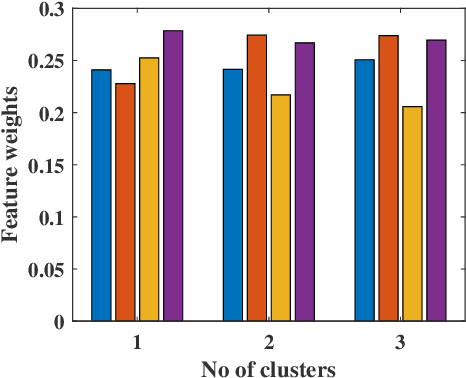


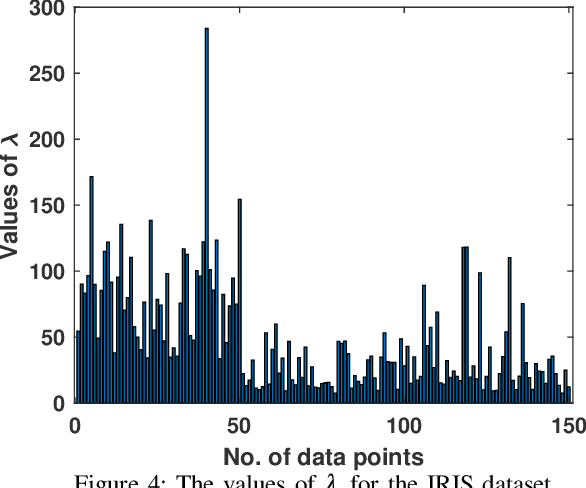
This paper presents a new fuzzy k-means algorithm for the clustering of high dimensional data in various subspaces. Since, In the case of high dimensional data, some features might be irrelevant and relevant but may have different significance in the clustering. For a better clustering, it is crucial to incorporate the contribution of these features in the clustering process. To combine these features, in this paper, we have proposed a new fuzzy k-means clustering algorithm in which the objective function of the fuzzy k-means is modified using two different entropy term. The first entropy term helps to minimize the within-cluster dispersion and maximize the negative entropy to determine clusters to contribute to the association of data points. The second entropy term helps to control the weight of the features because different features have different contributing weights in the clustering process for obtaining the better partition of the data. The efficacy of the proposed method is presented in terms of various clustering measures on multiple datasets and compared with various state-of-the-art methods.