 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-end Framework for Unconstrained Monocular 3D Hand Pose Estimation
Paper and Code
Nov 28, 2019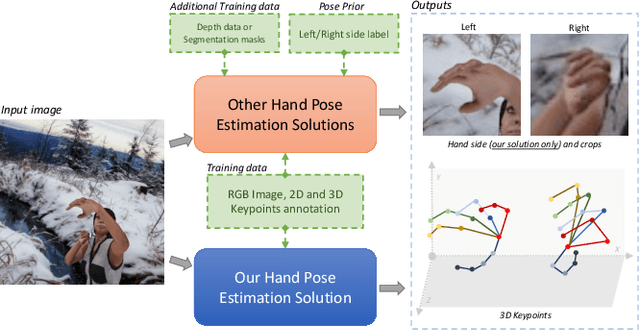
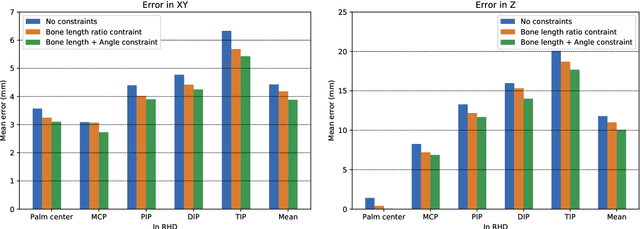

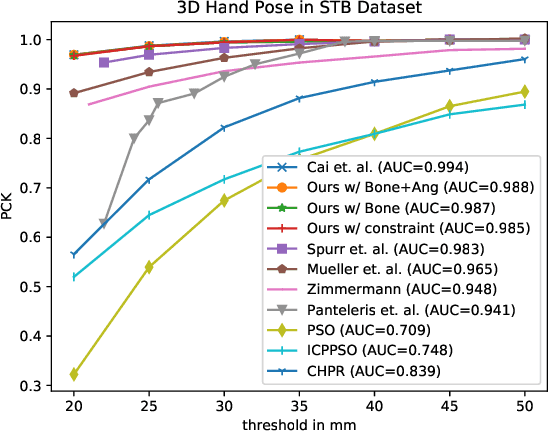
This work addresses the challenging problem of unconstrained 3D hand pose estimation using monocular RGB images. Most of the existing approaches assume some prior knowledge of hand (such as hand locations and side information) is available for 3D hand pose estimation. This restricts their use in unconstrained environments. We, therefore, present an end-to-end framework that robustly predicts hand prior information and accurately infers 3D hand pose by learning ConvNet models while only using keypoint annotations. To achieve robustness, the proposed framework uses a novel keypoint-based method to simultaneously predict hand regions and side labels, unlike existing methods that suffer from background color confusion caused by using segmentation or detection-based technology. Moreover, inspired by the biological structure of the human hand, we introduce two geometric constraints directly into the 3D coordinates prediction that further improves its performance in a weakly-supervised training. Experimental results show that our proposed framework not only performs robustly on unconstrained setting, but also outperforms the state-of-art methods on standard benchmark datasets.