 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Time-Series Feature Sets
Paper and Code
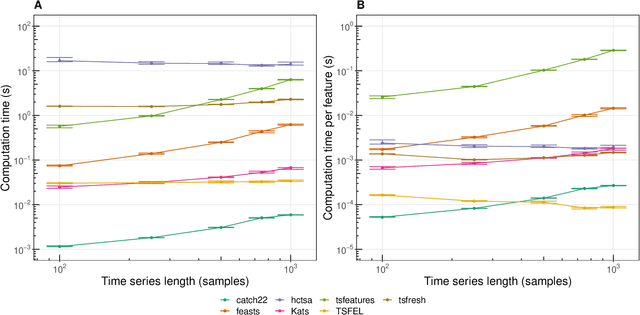
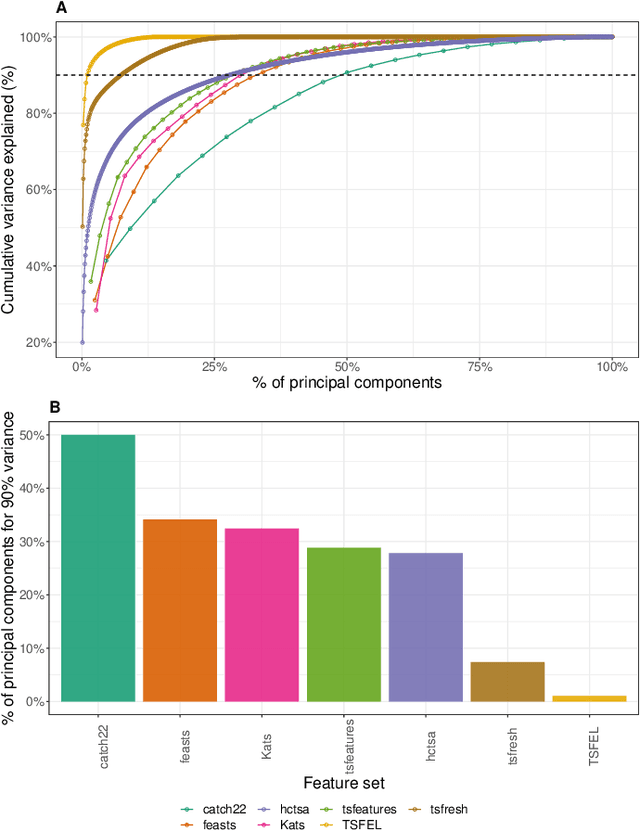
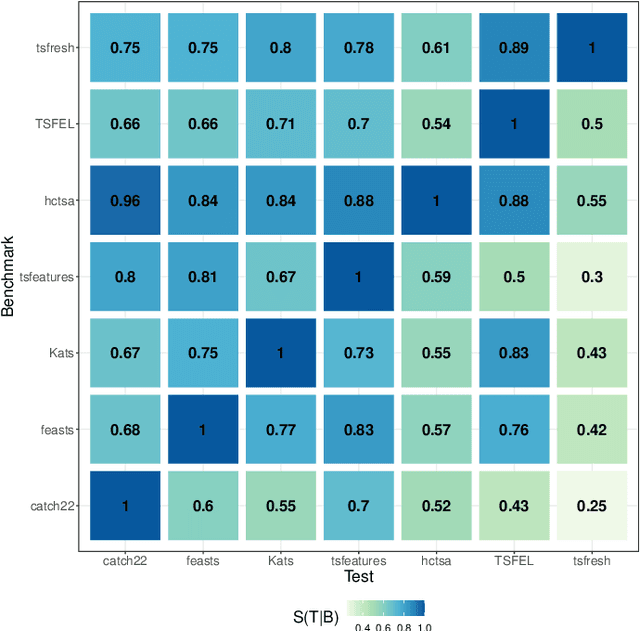
Solving time-series problems with features has been rising in popularity due to the availability of software for feature extraction. Feature-based time-series analysis can now be performed using many different feature sets, including hctsa (7730 features: Matlab), feasts (42 features: R), tsfeatures (63 features: R), Kats (40 features: Python), tsfresh (up to 1558 features: Python), TSFEL (390 features: Python), and the C-coded catch22 (22 features: Matlab, R, Python, and Julia). There is substantial overlap in the types of methods included in these sets (e.g., properties of the autocorrelation function and Fourier power spectrum), but they are yet to be systematically compared. Here we compare these seven sets on computational speed, assess the redundancy of features contained in each, and evaluate the overlap and redundancy between them. We take an empirical approach to feature similarity based on outputs across a diverse set of real-world and simulated time series. We find that feature sets vary across three orders of magnitude in their computation time per feature on a laptop for a 1000-sample series, from the fastest sets catch22 and TSFEL (~0.1ms per feature) to tsfeatures (~3s per feature). Using PCA to evaluate feature redundancy within each set, we find the highest within-set redundancy for TSFEL and tsfresh. For example, in TSFEL, 90% of the variance across 390 features can be captured with just four PCs. Finally, we introduce a metric for quantifying overlap between pairs of feature sets, which indicates substantial overlap. We found that the largest feature set, hctsa, is the most comprehensive, and that tsfresh is the most distinctive, due to its incorporation of many low-level Fourier coefficients. Our results provide empirical understanding of the differences between existing feature sets, information that can be used to better tailor feature sets to their applications.