 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Semi-supervised Divisive Clustering Algorithm
Paper and Code
Jan 06, 2015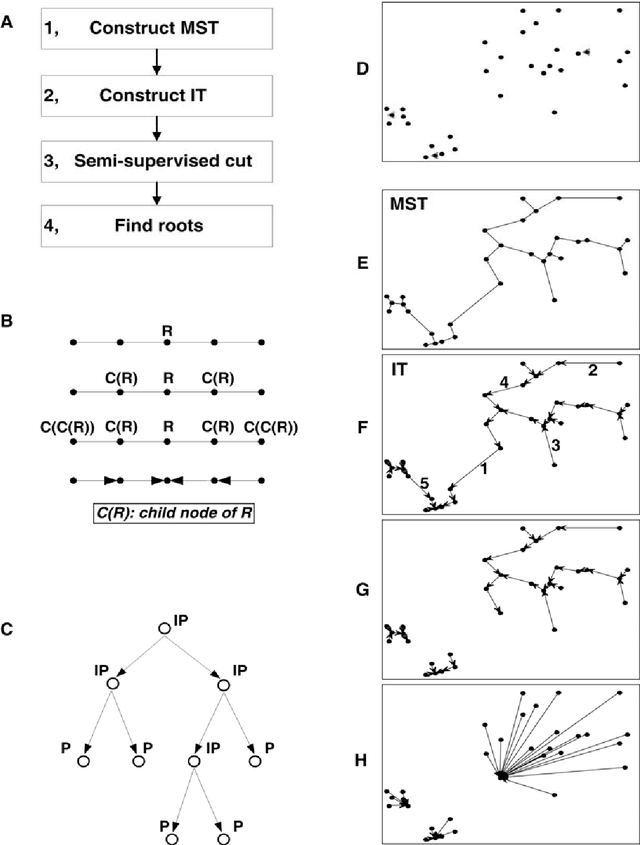
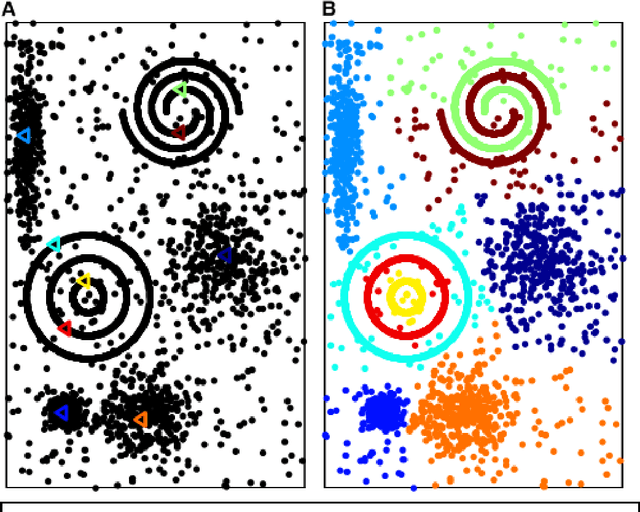
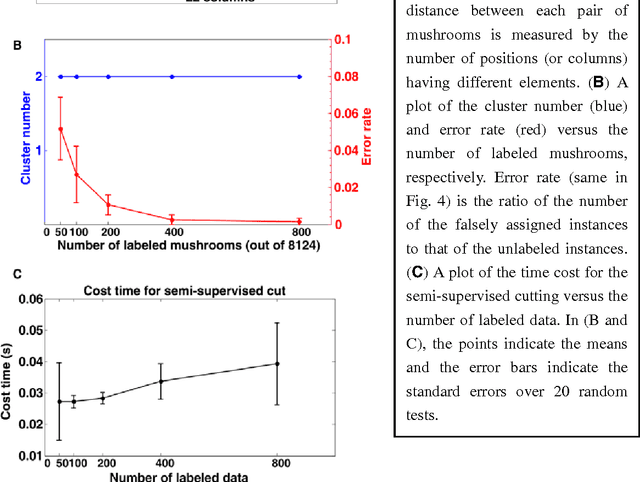
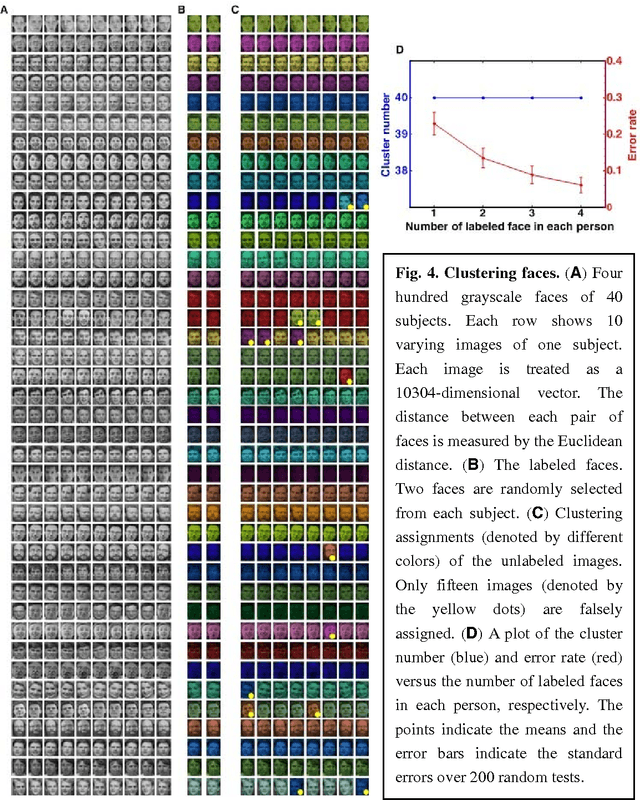
Nowadays, data are generated massively and rapidly from scientific fields as bioinformatics, neuroscience and astronomy to business and engineering fields. Cluster analysis, as one of the major data analysis tools, is therefore more significant than ever. We propose in this work an effective Semi-supervised Divisive Clustering algorithm (SDC). Data points are first organized by a minimal spanning tree. Next, this tree structure is transitioned to the in-tree structure, and then divided into sub-trees under the supervision of the labeled data, and in the end, all points in the sub-trees are directly associated with specific cluster centers. SDC is fully automatic, non-iterative, involving no free parameter, insensitive to noise, able to detect irregularly shaped cluster structures, applicable to the data sets of high dimensionality and different attributes. The power of SDC is demonstrated on several datasets.