 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective-Efficient Approach for Dense Multi-Label Action Detection
Paper and Code
Jun 10, 2024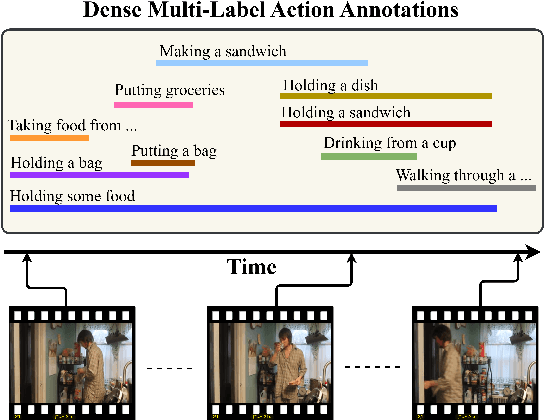

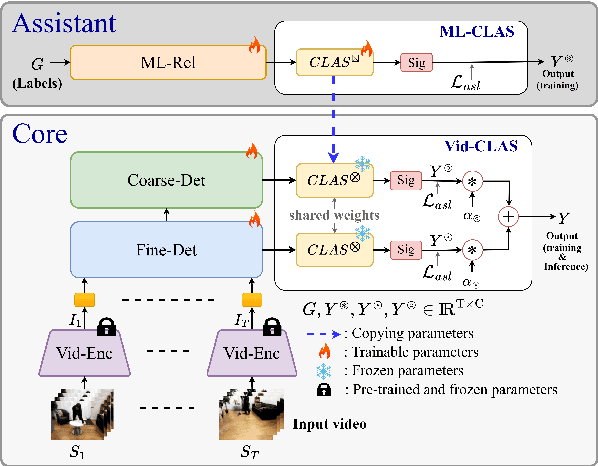

Unlike the sparse label action detection task, where a single action occurs in each timestamp of a video, in a dense multi-label scenario, actions can overlap. To address this challenging task, it is necessary to simultaneously learn (i) temporal dependencies and (ii) co-occurrence action relationships. Recent approaches model temporal information by extracting multi-scale features through hierarchical transformer-based networks. However, the self-attention mechanism in transformers inherently loses temporal positional information. We argue that combining this with multiple sub-sampling processes in hierarchical designs can lead to further loss of positional information. Preserving this information is essential for accurate action detection. In this paper, we address this issue by proposing a novel transformer-based network that (a) employs a non-hierarchical structure when modelling different ranges of temporal dependencies and (b) embeds relative positional encoding in its transformer layers. Furthermore, to model co-occurrence action relationships, current methods explicitly embed class relations into the transformer network. However, these approaches are not computationally efficient, as the network needs to compute all possible pair action class relations. We also overcome this challenge by introducing a novel learning paradigm that allows the network to benefit from explicitly modelling temporal co-occurrence action dependencies without imposing their additional computational costs during inference. We evaluate the performance of our proposed approach on two challenging dense multi-label benchmark datasets and show that our method improves the current state-of-the-art results.