 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approximate Dynamic Programming Approach to Repeated Games with Vector Losses
Paper and Code
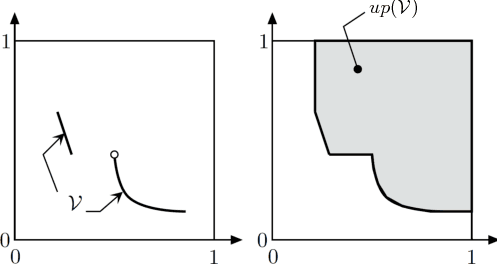


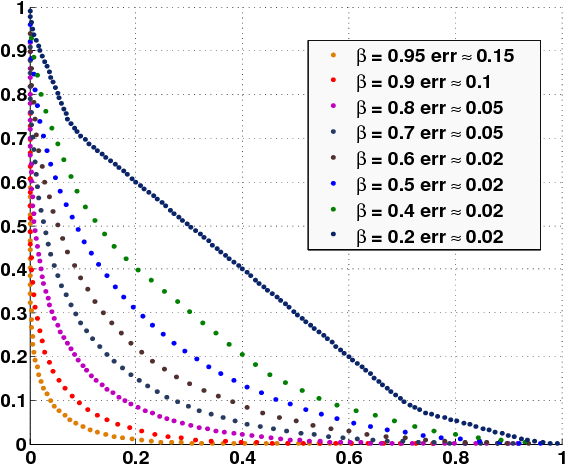
We describe an approximate dynamic programming (ADP) approach to compute approximately optimal strategies and approximations of the minimal losses that can be guaranteed in discounted repeated games with vector losses. At the core of our approach is a characterization of the lower Pareto frontier of the set of expected losses that a player can guarantee in these games as the unique fixed point of a set-valued dynamic programming (DP) operator. This fixed point can be approximated by an iterative application of this DP operator compounded by a polytopic set approximation, beginning with a single point. Each iteration can be computed by solving a set of linear programs corresponding to the vertices of the polytope. We derive rigorous bounds on the error of the resulting approximation and the performance of the corresponding approximately optimal strategies. We discuss an application to regret minimization in repeated decision-making in adversarial environments, where we show that this approach can be used to compute approximately optimal strategies and approximations of the minimax optimal regret when the action sets are finite. We illustrate this approach by computing provably approximately optimal strategies for the problem of prediction using expert advice under discounted $\{0,1\}-$losses. Our numerical evaluations demonstrate the sub-optimality of well-known off-the-shelf online learning algorithms like Hedge and a significantly improved performance on using our approximately optimal strategies in these settings. Our work thus demonstrates the significant potential in using the ADP framework to design effective online learning algorithms.