Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Aggregate and Iterative Disaggregate Algorithm with Proven Optimality in Machine Learning
Paper and Code
Jul 05, 2016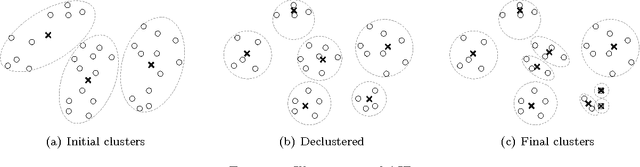
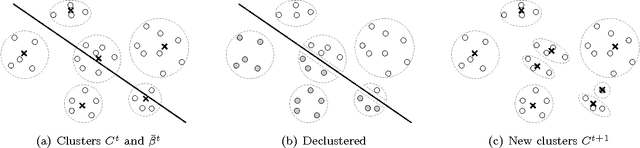
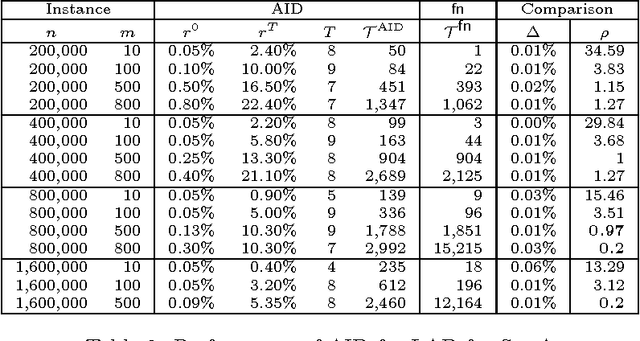
We propose a clustering-based iterative algorithm to solve certain optimization problems in machine learning, where we start the algorithm by aggregating the original data, solving the problem on aggregated data, and then in subsequent steps gradually disaggregate the aggregated data. We apply the algorithm to common machine learning problems such as the least absolute deviation regression problem, support vector machines, and semi-supervised support vector machines. We derive model-specific data aggregation and disaggregation procedures. We also show optimality, convergence, and the optimality gap of the approximated solution in each iteration. A computational study is provided.
* Machine Learning 105 (2016) 199 - 232
View paper on