 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Variational Inference: When and Why?
Paper and Code
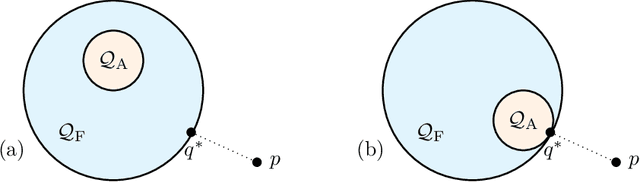

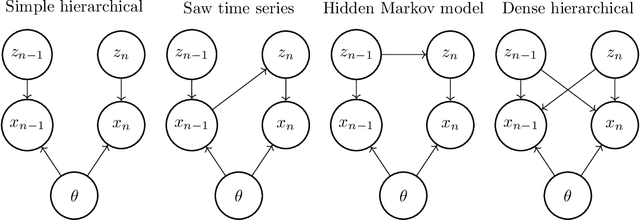
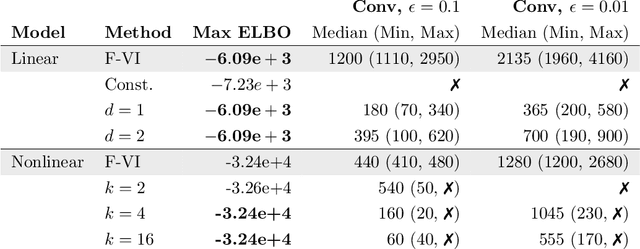
Amortized variational inference (A-VI) is a method for approximating the intractable posterior distributions that arise in probabilistic models. The defining feature of A-VI is that it learns a global inference function that maps each observation to its local latent variable's approximate posterior. This stands in contrast to the more classical factorized (or mean-field) variational inference (F-VI), which directly learns the parameters of the approximating distribution for each latent variable. In deep generative models, A-VI is used as a computational trick to speed up inference for local latent variables. In this paper, we study A-VI as a general alternative to F-VI for approximate posterior inference. A-VI cannot produce an approximation with a lower Kullback-Leibler divergence than F-VI's optimal solution, because the amortized family is a subset of the factorized family. Thus a central theoretical problem is to characterize when A-VI still attains F-VI's optimal solution. We derive conditions on both the model and the inference function under which A-VI can theoretically achieve F-VI's optimum. We show that for a broad class of hierarchical models, including deep generative models, it is possible to close the gap between A-VI and F-VI. Further, for an even broader class of models, we establish when and how to expand the domain of the inference function to make amortization a feasible strategy. Finally, we prove that for certain models -- including hidden Markov models and Gaussian processes -- A-VI cannot match F-VI's solution, no matter how expressive the inference function is. We also study A-VI empirically. On several examples, we corroborate our theoretical results and investigate the performance of A-VI when varying the complexity of the inference function. When the gap between A-VI and F-VI can be closed, we find that the required complexity of the function need not scale with the number of observations, and that A-VI often converges faster than F-VI.