 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMBER: Adaptive Multi-Batch Experience Replay for Continuous Action Control
Paper and Code
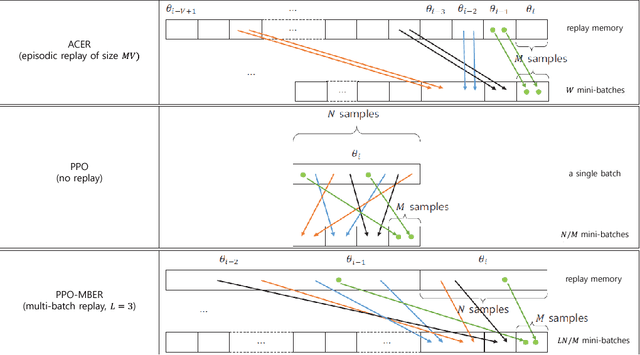



In this paper, a new adaptive multi-batch experience replay scheme is proposed for proximal policy optimization (PPO) for continuous action control. On the contrary to original PPO, the proposed scheme uses the batch samples of past policies as well as the current policy for the update for the next policy, where the number of the used past batches is adaptively determined based on the oldness of the past batches measured by the average importance sampling (IS) weight. The new algorithm constructed by combining PPO with the proposed multi-batch experience replay scheme maintains the advantages of original PPO such as random mini-batch sampling and small bias due to low IS weights by storing the pre-computed advantages and values and adaptively determining the mini-batch size. Numerical results show that the proposed method significantly increases the speed and stability of convergence on various continuous control tasks compared to original PPO.