 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALLoRA: Adaptive Learning Rate Mitigates LoRA Fatal Flaws
Paper and Code



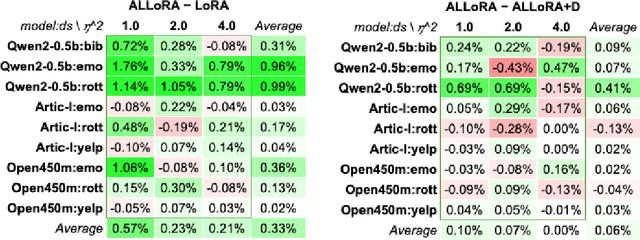
Low-Rank Adaptation (LoRA) is the bread and butter of Large Language Model (LLM) finetuning. LoRA learns an additive low-rank perturbation, $AB$, of a pretrained matrix parameter $W$ to align the model to a new task or dataset with $W+AB$. We identify three core limitations to LoRA for finetuning--a setting that employs limited amount of data and training steps. First, LoRA employs Dropout to prevent overfitting. We prove that Dropout is only suitable for long training episodes but fails to converge to a reliable regularizer for short training episodes. Second, LoRA's initialization of $B$ at $0$ creates a slow training dynamic between $A$ and $B$. That dynamic is also exacerbated by Dropout that further slows the escape from $0$ for $B$ which is particularly harmful for short training episodes. Third, the scaling factor multiplying each LoRA additive perturbation creates ``short-sighted'' interactions between the LoRA modules of different layers. Motivated by principled analysis of those limitations, we find an elegant solution: a Dropout-free, scaling-free, LoRA with Adaptive Learning rate--coined ALLoRA. By scaling the per sample and per parameter gradients with a coefficient inversely proportional to parameters' $\ell_2$ norm, ALLoRA alleviates those three limitations. As a by-product, ALLoRA removes two hyper-parameters from LoRA: the scaling factor and the dropout rate. Empirical results show that ALLoRA admits better accuracy than LoRA on various settings, including against recent LoRA variants such as Weight-Decomposed Low-Rank Adaptation (DoRA). Ablation studies show our solution is the optimal in a family of weight-dependent / output-dependent approaches on various LLMs including the latest Llama3.