Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating the Inequality of Attention Heads for Neural Machine Translation
Paper and Code
Sep 21, 2020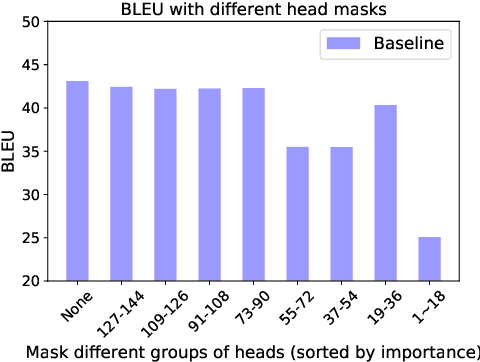
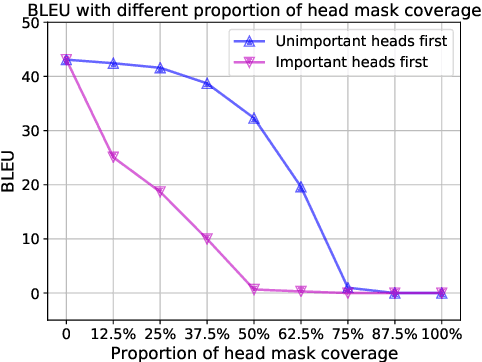


Recent studies show that the attention heads in Transformer are not equal. We relate this phenomenon to the imbalance training of multi-head attention and the model dependence on specific heads. To tackle this problem, we propose a simple masking method: HeadMask, in two specific ways. Experiments show that translation improvements are achieved on multiple language pairs. Subsequent empirical analyses also support our assumption and confirm the effectiveness of the method.
View paper on