 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAliasing and Label-Independent Decomposition of Risk: Beyond the bias-variance trade-off
Paper and Code
Aug 15, 2024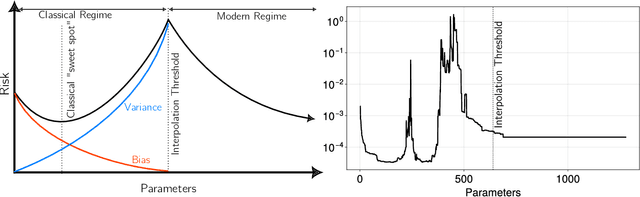
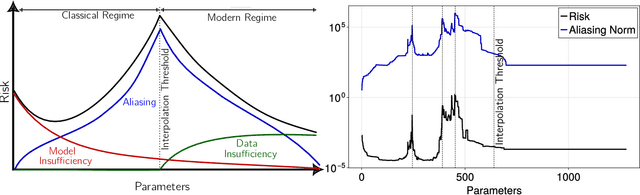
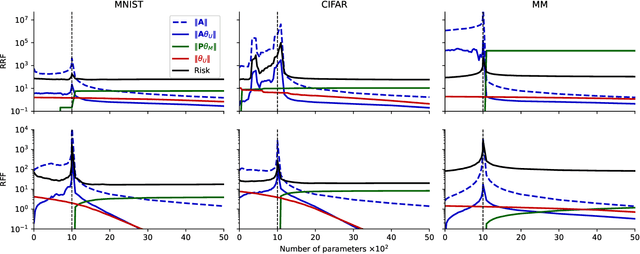
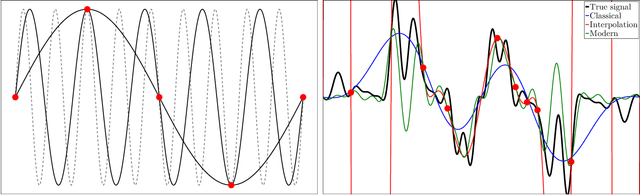
A central problem in data science is to use potentially noisy samples of an unknown function to predict function values for unseen inputs. In classical statistics, the predictive error is understood as a trade-off between the bias and the variance that balances model simplicity with its ability to fit complex functions. However, over-parameterized models exhibit counter-intuitive behaviors, such as "double descent" in which models of increasing complexity exhibit decreasing generalization error. We introduce an alternative paradigm called the generalized aliasing decomposition. We explain the asymptotically small error of complex models as a systematic "de-aliasing" that occurs in the over-parameterized regime. In the limit of large models, the contribution due to aliasing vanishes, leaving an expression for the asymptotic total error we call the invertibility failure of very large models on few training points. Because the generalized aliasing decomposition can be explicitly calculated from the relationship between model class and samples without seeing any data labels, it can answer questions related to experimental design and model selection before collecting data or performing experiments. We demonstrate this approach using several examples, including classical regression problems and a cluster expansion model used in materials science.