 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic encoding of protected characteristics and its implications on disparities across subgroups
Paper and Code

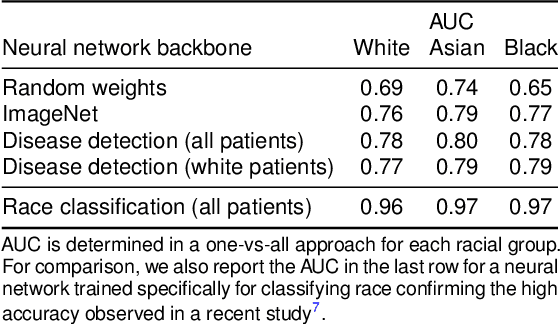

It has been rightfully emphasized that the use of AI for clinical decision making could amplify health disparities. A machine learning model may pick up undesirable correlations, for example, between a patient's racial identity and clinical outcome. Such correlations are often present in (historical) data used for model development. There has been an increase in studies reporting biases in disease detection models across patient subgroups. Besides the scarcity of data from underserved populations, very little is known about how these biases are encoded and how one may reduce or even remove disparate performance. There is some speculation whether algorithms may recognize patient characteristics such as biological sex or racial identity, and then directly or indirectly use this information when making predictions. But it remains unclear how we can establish whether such information is actually used. This article aims to shed some light on these issues by exploring new methodology allowing intuitive inspections of the inner working of machine learning models for image-based detection of disease. We also evaluate an effective yet debatable technique for addressing disparities leveraging the automatic prediction of patient characteristics, resulting in models with comparable true and false positive rates across subgroups. Our findings may stimulate the discussion about safe and ethical use of AI.