 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggretriever: A Simple Approach to Aggregate Textual Representation for Robust Dense Passage Retrieval
Paper and Code
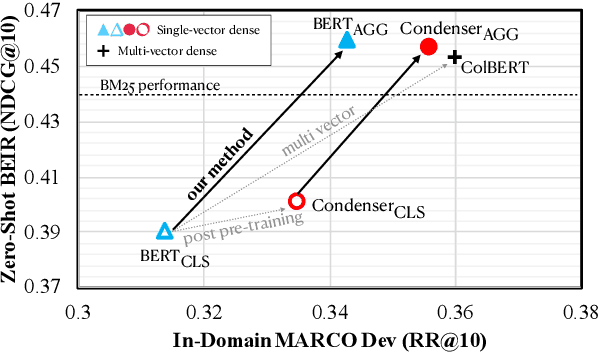
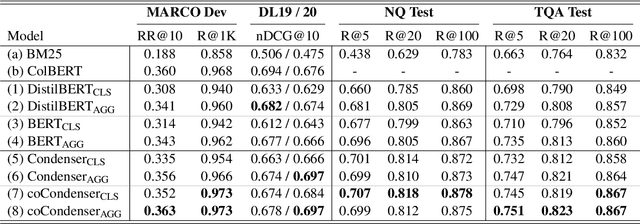

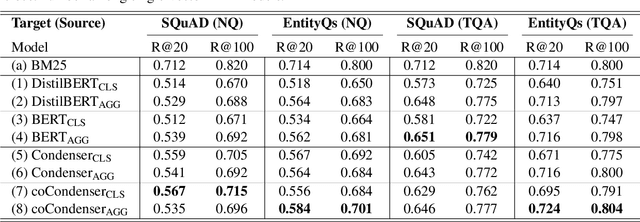
Pre-trained transformers has declared its success in many NLP tasks. One thread of work focuses on training bi-encoder models (i.e., dense retrievers) to effectively encode sentences or passages into single-vector dense vectors for efficient approximate nearest neighbor (ANN) search. However, recent work has demonstrated that transformers pre-trained with mask language modeling (MLM) are not capable of effectively aggregating text information into a single dense vector due to task-mismatch between pre-training and fine-tuning. Therefore, computationally expensive techniques have been adopted to train dense retrievers, such as large batch size, knowledge distillation or post pre-training. In this work, we present a simple approach to effectively aggregate textual representation from the pre-trained transformer into a dense vector. Extensive experiments show that our approach improves the robustness of the single-vector approach under both in-domain and zero-shot evaluations without any computationally expensive training techniques. Our work demonstrates that MLM pre-trained transformers can be used to effectively encode text information into a single-vector for dense retrieval. Code are available at: https://github.com/castorini/dhr