 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Modeling as Auxiliary Task for Deep Reinforcement Learning
Paper and Code
Jul 22, 2019
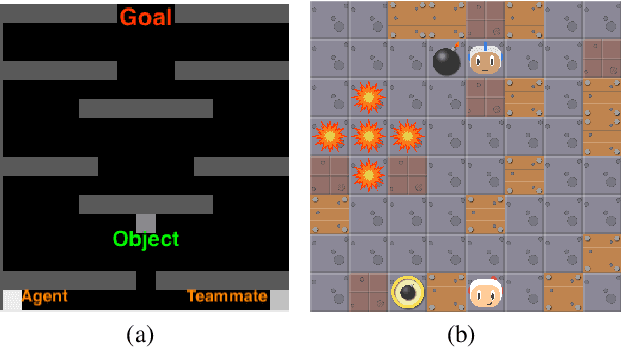
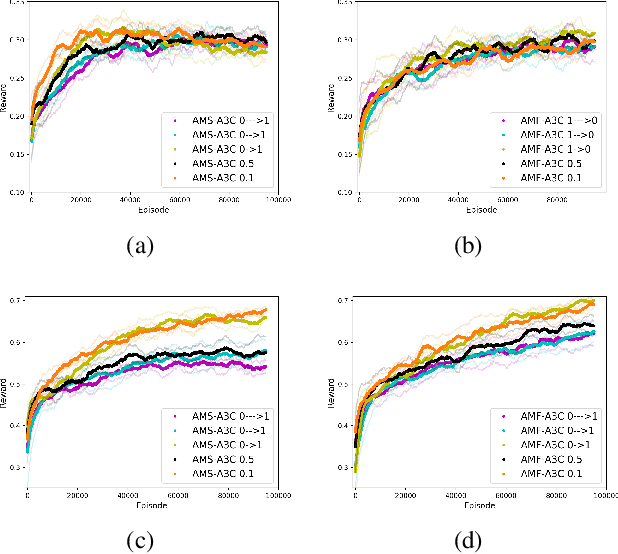
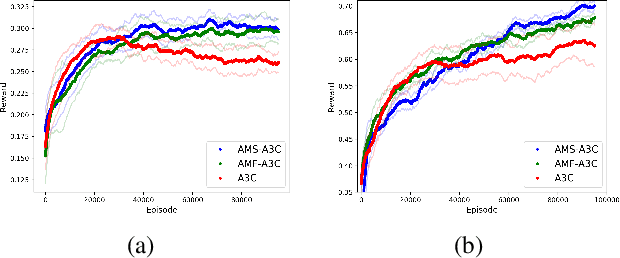
In this paper we explore how actor-critic methods in deep reinforcement learning, in particular Asynchronous Advantage Actor-Critic (A3C), can be extended with agent modeling. Inspired by recent works on representation learning and multiagent deep reinforcement learning, we propose two architectures to perform agent modeling: the first one based on parameter sharing, and the second one based on agent policy features. Both architectures aim to learn other agents' policies as auxiliary tasks, besides the standard actor (policy) and critic (values). We performed experiments in both cooperative and competitive domains. The former is a problem of coordinated multiagent object transportation and the latter is a two-player mini version of the Pommerman game. Our results show that the proposed architectures stabilize learning and outperform the standard A3C architecture when learning a best response in terms of expected rewards.