 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffect-Conditioned Image Generation
Paper and Code

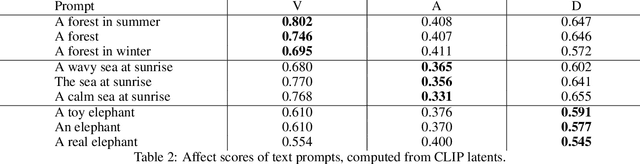

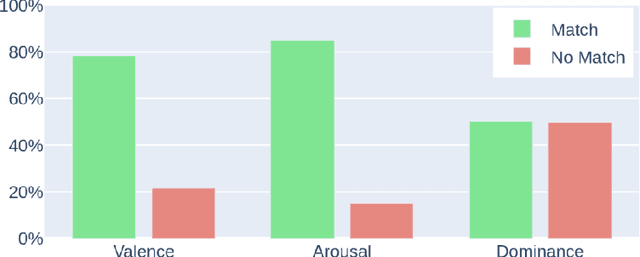
In creativity support and computational co-creativity contexts, the task of discovering appropriate prompts for use with text-to-image generative models remains difficult. In many cases the creator wishes to evoke a certain impression with the image, but the task of conferring that succinctly in a text prompt poses a challenge: affective language is nuanced, complex, and model-specific. In this work we introduce a method for generating images conditioned on desired affect, quantified using a psychometrically validated three-component approach, that can be combined with conditioning on text descriptions. We first train a neural network for estimating the affect content of text and images from semantic embeddings, and then demonstrate how this can be used to exert control over a variety of generative models. We show examples of how affect modifies the outputs, provide quantitative and qualitative analysis of its capabilities, and discuss possible extensions and use cases.