 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training of Variational Auto-encoders for High Fidelity Image Generation
Paper and Code
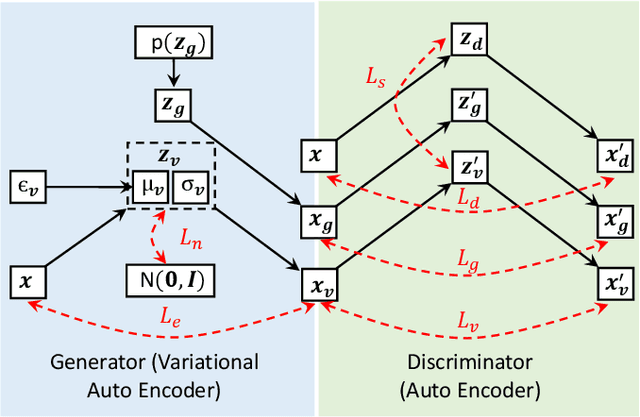
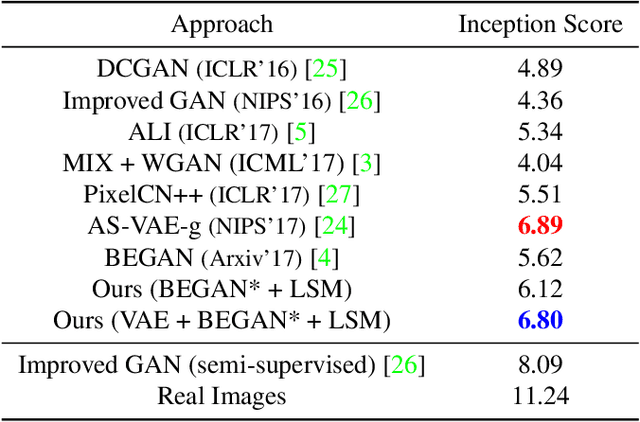


Variational auto-encoders (VAEs) provide an attractive solution to image generation problem. However, they tend to produce blurred and over-smoothed images due to their dependence on pixel-wise reconstruction loss. This paper introduces a new approach to alleviate this problem in the VAE based generative models. Our model simultaneously learns to match the data, reconstruction loss and the latent distributions of real and fake images to improve the quality of generated samples. To compute the loss distributions, we introduce an auto-encoder based discriminator model which allows an adversarial learning procedure. The discriminator in our model also provides perceptual guidance to the VAE by matching the learned similarity metric of the real and fake samples in the latent space. To stabilize the overall training process, our model uses an error feedback approach to maintain the equilibrium between competing networks in the model. Our experiments show that the generated samples from our proposed model exhibit a diverse set of attributes and facial expressions and scale up to high-resolution images very well.