 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training for Community Question Answer Selection Based on Multi-scale Matching
Paper and Code
Apr 22, 2018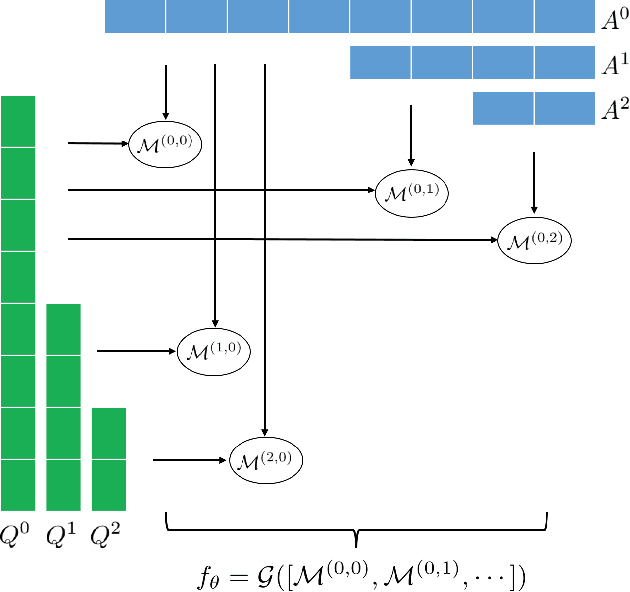
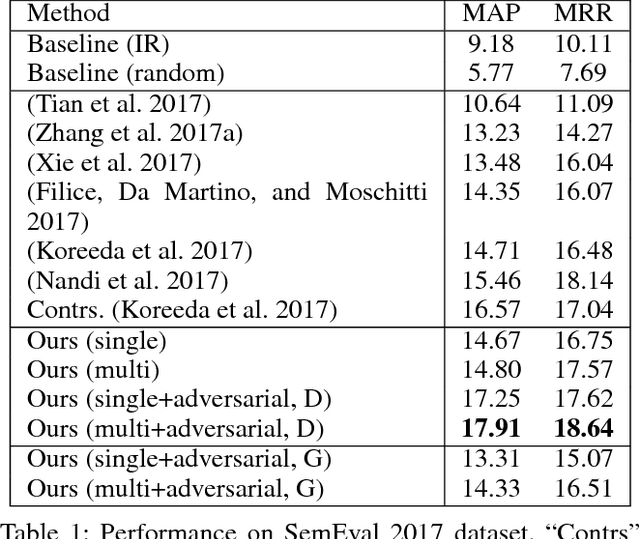
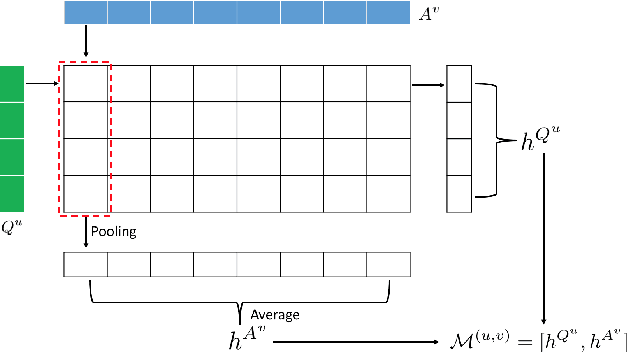
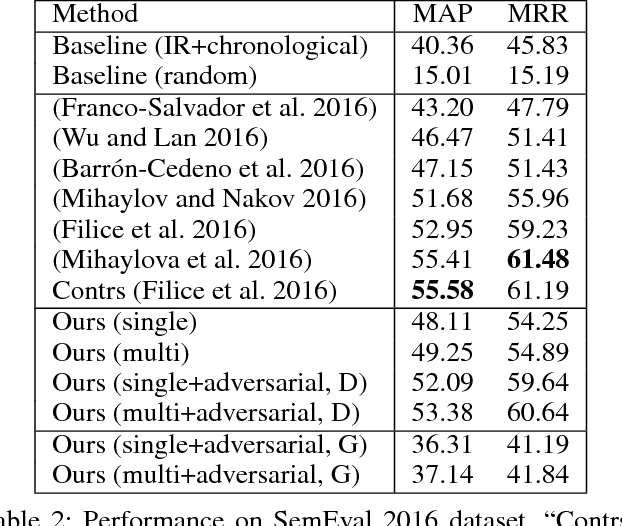
Community-based question answering (CQA) websites represent an important source of information. As a result, the problem of matching the most valuable answers to their corresponding questions has become an increasingly popular research topic. We frame this task as a binary (relevant/irrelevant) classification problem, and propose a Multi-scale Matching model that inspects the correlation between words and ngrams (word-to-ngrams) of different levels of granularity. This is in addition to word-to-word correlations which are used in most prior work. In this way, our model is able to capture rich context information conveyed in ngrams, therefore can better differentiate good answers from bad ones. Furthermore, we present an adversarial training framework to iteratively generate challenging negative samples to fool the proposed classification model. This is completely different from previous methods, where negative samples are uniformly sampled from the dataset during training process. The proposed method is evaluated on SemEval 2017 and Yahoo Answer dataset and achieves state-of-the-art performance.