 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Sample Enhanced Domain Adaptation: A Case Study on Predictive Modeling with Electronic Health Records
Paper and Code
Jan 13, 2021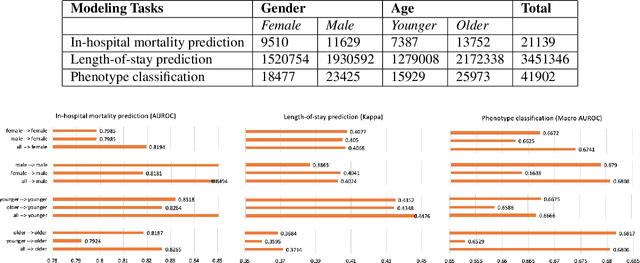
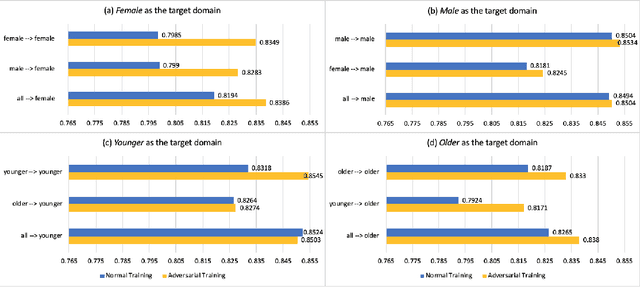

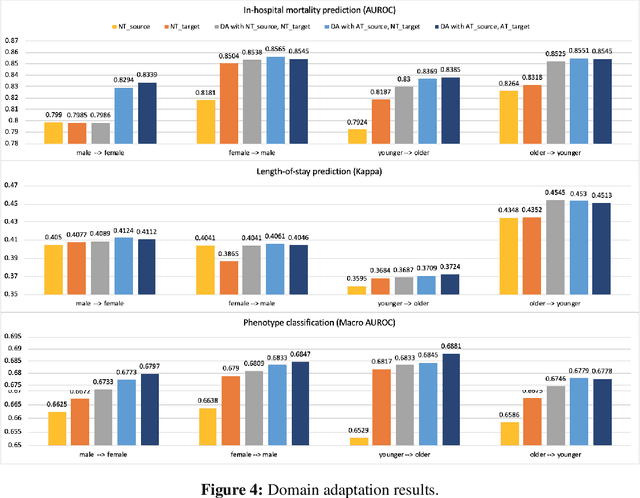
With the successful adoption of machine learning on electronic health records (EHRs), numerous computational models have been deployed to address a variety of clinical problems. However, due to the heterogeneity of EHRs, models trained on different patient groups suffer from poor generalizability. How to mitigate domain shifts between the source patient group where the model is built upon and the target one where the model will be deployed becomes a critical issue. In this paper, we propose a data augmentation method to facilitate domain adaptation, which leverages knowledge from the source patient group when training model on the target one. Specifically, adversarially generated samples are used during domain adaptation to fill the generalization gap between the two patient groups. The proposed method is evaluated by a case study on different predictive modeling tasks on MIMIC-III EHR dataset. Results confirm the effectiveness of our method and the generality on different tasks.