 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Online Multi-Task Reinforcement Learning
Paper and Code



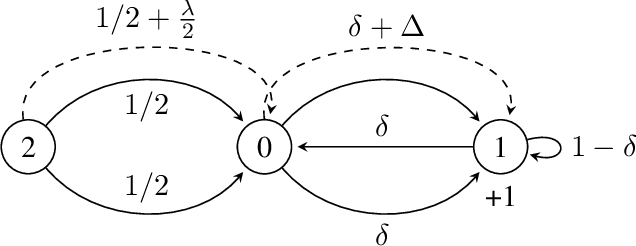
We consider the adversarial online multi-task reinforcement learning setting, where in each of $K$ episodes the learner is given an unknown task taken from a finite set of $M$ unknown finite-horizon MDP models. The learner's objective is to minimize its regret with respect to the optimal policy for each task. We assume the MDPs in $\mathcal{M}$ are well-separated under a notion of $\lambda$-separability, and show that this notion generalizes many task-separability notions from previous works. We prove a minimax lower bound of $\Omega(K\sqrt{DSAH})$ on the regret of any learning algorithm and an instance-specific lower bound of $\Omega(\frac{K}{\lambda^2})$ in sample complexity for a class of uniformly-good cluster-then-learn algorithms. We use a novel construction called 2-JAO MDP for proving the instance-specific lower bound. The lower bounds are complemented with a polynomial time algorithm that obtains $\tilde{O}(\frac{K}{\lambda^2})$ sample complexity guarantee for the clustering phase and $\tilde{O}(\sqrt{MK})$ regret guarantee for the learning phase, indicating that the dependency on $K$ and $\frac{1}{\lambda^2}$ is tight.