 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Inverse Reinforcement Learning for Decision Making in Autonomous Driving
Paper and Code
Nov 19, 2019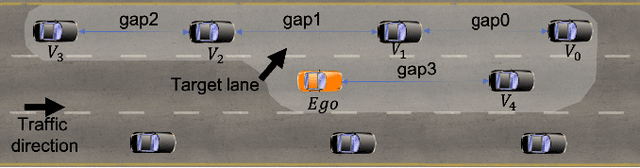
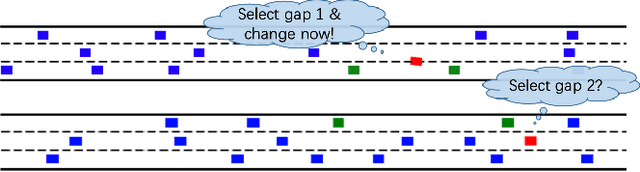
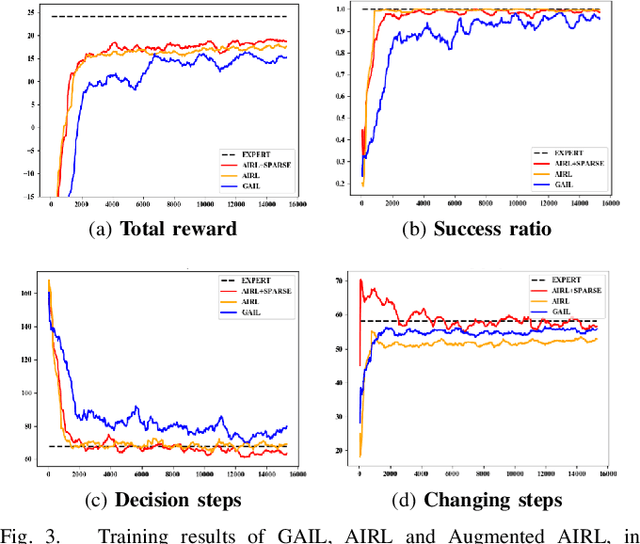
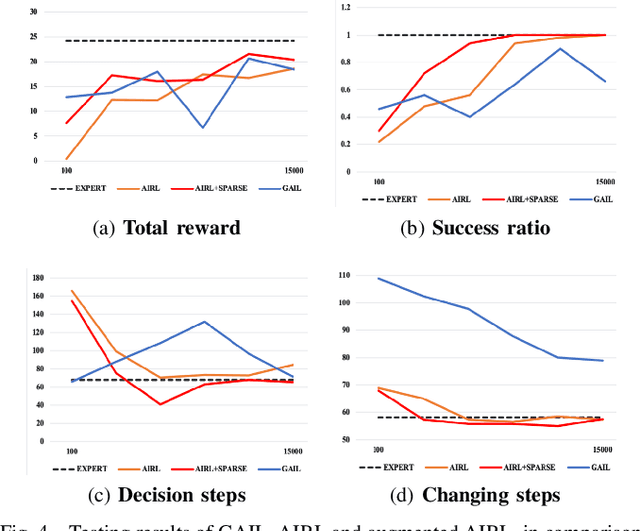
Generative Adversarial Imitation Learning (GAIL) is an efficient way to learn sequential control strategies from demonstration. Adversarial Inverse Reinforcement Learning (AIRL) is similar to GAIL but also learns a reward function at the same time and has better training stability. In previous work, however, AIRL has mostly been demonstrated on robotic control in artificial environments. In this paper, we apply AIRL to a practical and challenging problem -- the decision-making in autonomous driving, and also augment AIRL with a semantic reward to improve its performance. We use four metrics to evaluate its learning performance in a simulated driving environment. Results show that the vehicle agent can learn decent decision-making behaviors from scratch, and can reach a level of performance comparable with that of an expert. Additionally, the comparison with GAIL shows that AIRL converges faster, achieves better and more stable performance than GAIL.