 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Feature Desensitization
Paper and Code

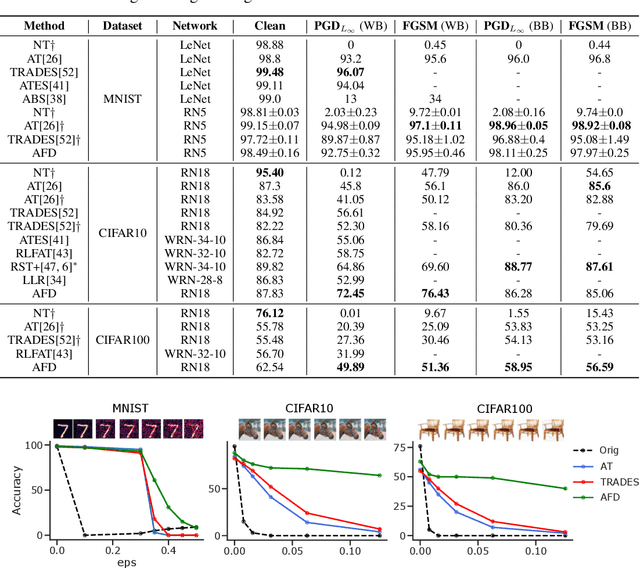

Deep neural networks can now perform many tasks that were once thought to be only feasible for humans. Unfortunately, while reaching impressive performance under standard settings, such networks are known to be susceptible to adversarial attacks -- slight but carefully constructed perturbations of the inputs which drastically decrease the network performance and reduce their trustworthiness. Here we propose to improve network robustness to input perturbations via an adversarial training procedure which we call Adversarial Feature Desensitization (AFD). We augment the normal supervised training with an adversarial game between the embedding network and an additional adversarial decoder which is trained to discriminate between the clean and perturbed inputs from their high-level embeddings. Our theoretical and empirical evidence acknowledges the effectiveness of this approach in learning robust features on MNIST, CIFAR10, and CIFAR100 datasets -- substantially improving the state-of-the-art in robust classification against previously observed adversarial attacks. More importantly, we demonstrate that AFD has better generalization ability than previous methods, as the learned features maintain their robustness against a large range of perturbations, including perturbations not seen during training. These results indicate that reducing feature sensitivity using adversarial training is a promising approach for ameliorating the problem of adversarial attacks in deep neural networks.