 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples Target Topological Holes in Deep Networks
Paper and Code
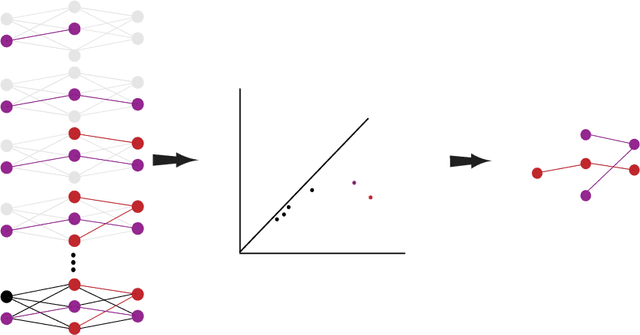
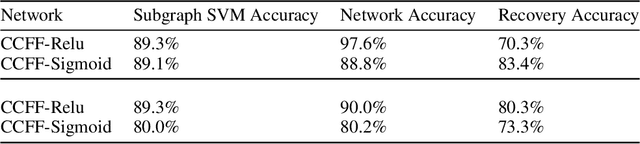
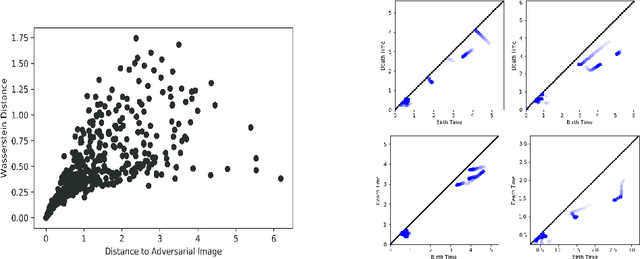

It is currently unclear why adversarial examples are easy to construct for deep networks that are otherwise successful with respect to their training domain. However, it is suspected that these adversarial examples lie within some small perturbation from the network's decision boundaries or exist in low-density regions with respect to the training distribution. Using persistent homology, we find that deep networks effectively have ``holes'' in their activation graphs, making them blind to regions of the input space that can be exploited by adversarial examples. These holes are effectively dense in the input space, making it easy to find a perturbed image that can be misclassified. By studying the topology of network activation, we find global patterns in the form of activation subgraphs which can both reliably determine whether an example is adversarial and can recover the true category of the example well above chance, implying that semantic information about the input is embedded globally via the activation pattern in deep networks.