 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Defense Teacher for Cross-Domain Object Detection under Poor Visibility Conditions
Paper and Code
Mar 23, 2024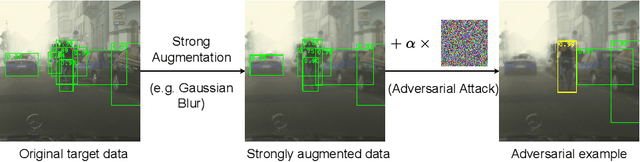
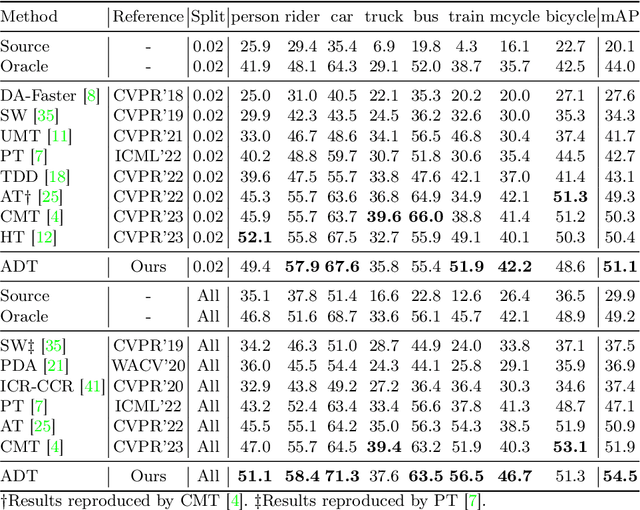
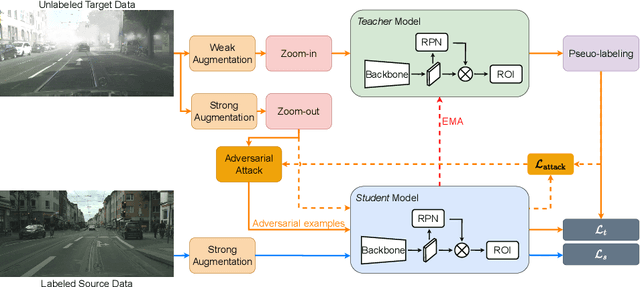
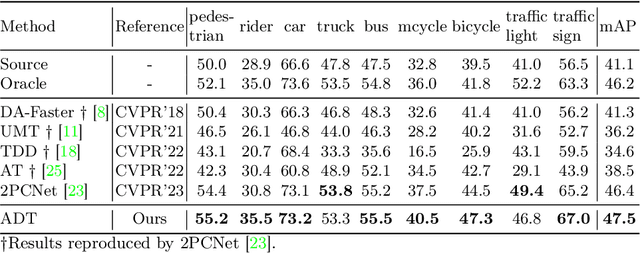
Existing object detectors encounter challenges in handling domain shifts between training and real-world data, particularly under poor visibility conditions like fog and night. Cutting-edge cross-domain object detection methods use teacher-student frameworks and compel teacher and student models to produce consistent predictions under weak and strong augmentations, respectively. In this paper, we reveal that manually crafted augmentations are insufficient for optimal teaching and present a simple yet effective framework named Adversarial Defense Teacher (ADT), leveraging adversarial defense to enhance teaching quality. Specifically, we employ adversarial attacks, encouraging the model to generalize on subtly perturbed inputs that effectively deceive the model. To address small objects under poor visibility conditions, we propose a Zoom-in Zoom-out strategy, which zooms-in images for better pseudo-labels and zooms-out images and pseudo-labels to learn refined features. Our results demonstrate that ADT achieves superior performance, reaching 54.5% mAP on Foggy Cityscapes, surpassing the previous state-of-the-art by 2.6% mAP.