 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADBCMM : Acronym Disambiguation by Building Counterfactuals and Multilingual Mixing
Paper and Code
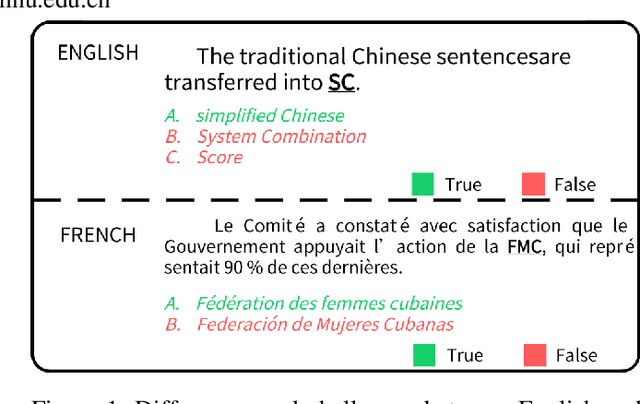
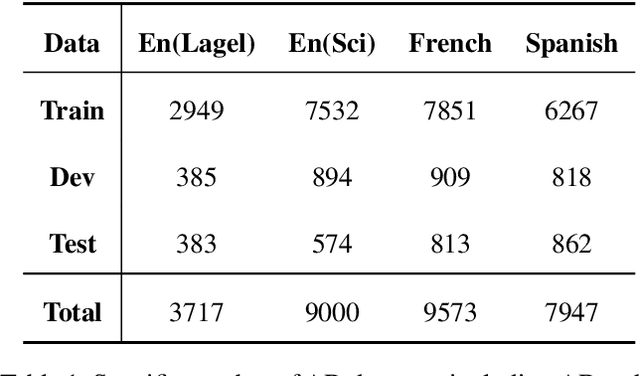
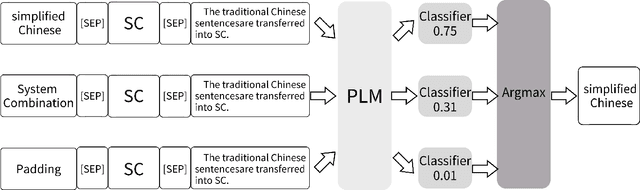
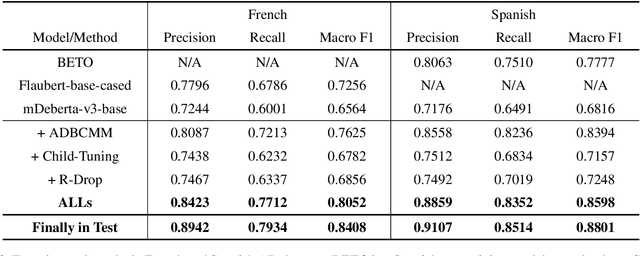
Scientific documents often contain a large number of acronyms. Disambiguation of these acronyms will help researchers better understand the meaning of vocabulary in the documents. In the past, thanks to large amounts of data from English literature, acronym task was mainly applied in English literature. However, for other low-resource languages, this task is difficult to obtain good performance and receives less attention due to the lack of large amount of annotation data. To address the above issue, this paper proposes an new method for acronym disambiguation, named as ADBCMM, which can significantly improve the performance of low-resource languages by building counterfactuals and multilingual mixing. Specifically, by balancing data bias in low-resource langauge, ADBCMM will able to improve the test performance outside the data set. In SDU@AAAI-22 - Shared Task 2: Acronym Disambiguation, the proposed method won first place in French and Spanish. You can repeat our results here https://github.com/WENGSYX/ADBCMM.