 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAT: Time-Series-Aware Adaptive Transformer Architecture for Sign Language Translation
Paper and Code
Apr 16, 2025


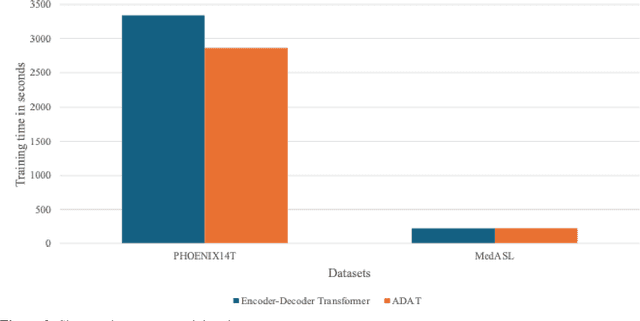
Current sign language machine translation systems rely on recognizing hand movements, facial expressions and body postures, and natural language processing, to convert signs into text. Recent approaches use Transformer architectures to model long-range dependencies via positional encoding. However, they lack accuracy in recognizing fine-grained, short-range temporal dependencies between gestures captured at high frame rates. Moreover, their high computational complexity leads to inefficient training. To mitigate these issues, we propose an Adaptive Transformer (ADAT), which incorporates components for enhanced feature extraction and adaptive feature weighting through a gating mechanism to emphasize contextually relevant features while reducing training overhead and maintaining translation accuracy. To evaluate ADAT, we introduce MedASL, the first public medical American Sign Language dataset. In sign-to-gloss-to-text experiments, ADAT outperforms the encoder-decoder transformer, improving BLEU-4 accuracy by 0.1% while reducing training time by 14.33% on PHOENIX14T and 3.24% on MedASL. In sign-to-text experiments, it improves accuracy by 8.7% and reduces training time by 2.8% on PHOENIX14T and achieves 4.7% higher accuracy and 7.17% faster training on MedASL. Compared to encoder-only and decoder-only baselines in sign-to-text, ADAT is at least 6.8% more accurate despite being up to 12.1% slower due to its dual-stream structure.