 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Variants of Optimal Feedback Policies
Paper and Code
Apr 06, 2021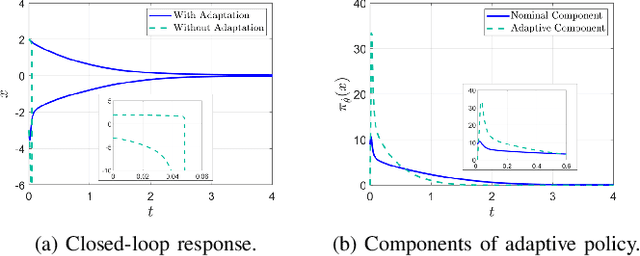

We combine adaptive control directly with optimal or near-optimal value functions to enhance stability and closed-loop performance in systems with parametric uncertainties. Leveraging the fundamental result that a value function is also a control Lyapunov function (CLF), combined with the fact that direct adaptive control can be immediately used once a CLF is known, we prove asymptotic closed-loop convergence of adaptive feedback controllers derived from optimization-based policies. Both matched and unmatched parametric variations are addressed, where the latter exploits a new technique based on adaptation rate scaling. The results may have particular resonance in machine learning for dynamical systems, where nominal feedback controllers are typically optimization-based but need to remain effective (beyond mere robustness) in the presence of significant but structured variations in parameters.