 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Text Recognition through Visual Matching
Paper and Code

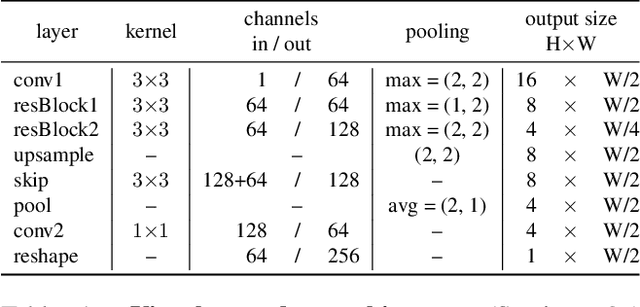
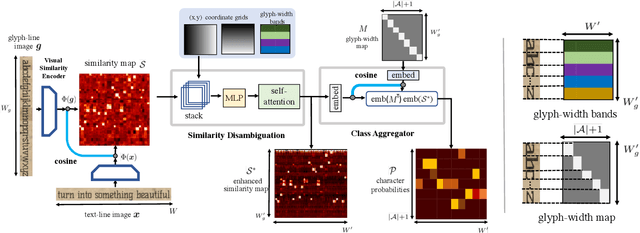
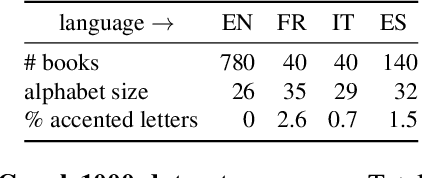
In this work, our objective is to address the problems of generalization and flexibility for text recognition in documents. We introduce a new model that exploits the repetitive nature of characters in languages, and decouples the visual representation learning and linguistic modelling stages. By doing this, we turn text recognition into a shape matching problem, and thereby achieve generalization in appearance and flexibility in classes. We evaluate the new model on both synthetic and real datasets across different alphabets and show that it can handle challenges that traditional architectures are not able to solve without expensive retraining, including: (i) it can generalize to unseen fonts without new exemplars from them; (ii) it can flexibly change the number of classes, simply by changing the exemplars provided; and (iii) it can generalize to new languages and new characters that it has not been trained for by providing a new glyph set. We show significant improvements over state-of-the-art models for all these cases.