 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Perturbation-Based Gradient Estimation for Discrete Latent Variable Models
Paper and Code
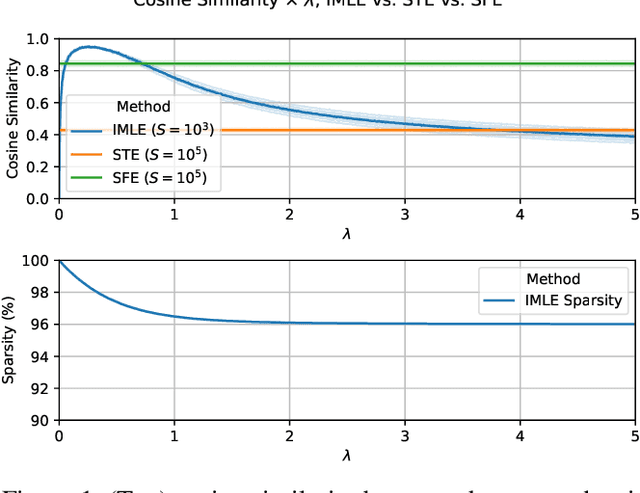
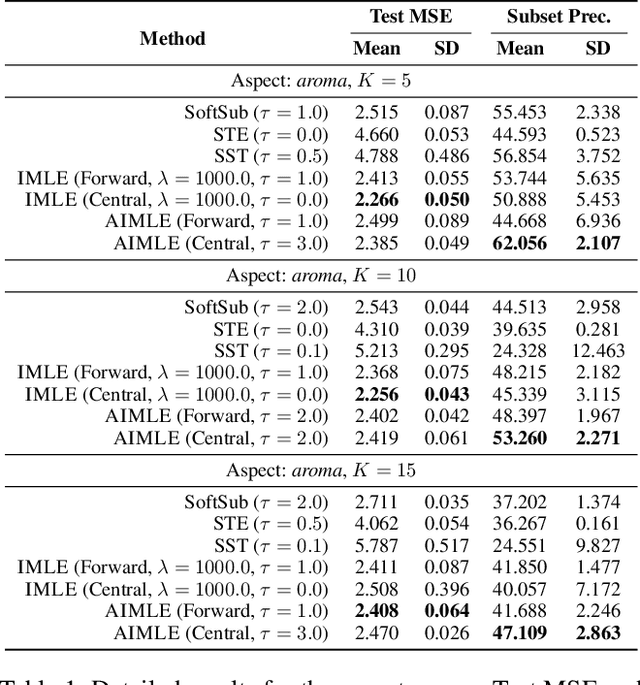
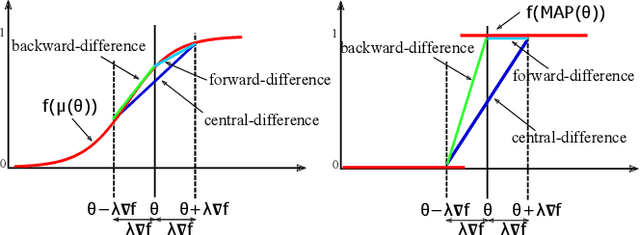

The integration of discrete algorithmic components in deep learning architectures has numerous applications. Recently, Implicit Maximum Likelihood Estimation (IMLE, Niepert, Minervini, and Franceschi 2021), a class of gradient estimators for discrete exponential family distributions, was proposed by combining implicit differentiation through perturbation with the path-wise gradient estimator. However, due to the finite difference approximation of the gradients, it is especially sensitive to the choice of the finite difference step size which needs to be specified by the user. In this work, we present Adaptive IMLE (AIMLE) the first adaptive gradient estimator for complex discrete distributions: it adaptively identifies the target distribution for IMLE by trading off the density of gradient information with the degree of bias in the gradient estimates. We empirically evaluate our estimator on synthetic examples, as well as on Learning to Explain, Discrete Variational Auto-Encoders, and Neural Relational Inference tasks. In our experiments, we show that our adaptive gradient estimator can produce faithful estimates while requiring orders of magnitude fewer samples than other gradient estimators.