 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Multi-Neighborhood Attention based Transformer for Graph Representation Learning
Paper and Code
Nov 15, 2022
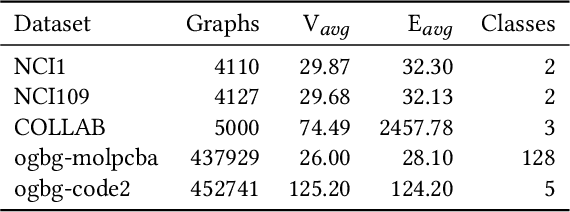


By incorporating the graph structural information into Transformers, graph Transformers have exhibited promising performance for graph representation learning in recent years. Existing graph Transformers leverage specific strategies, such as Laplacian eigenvectors and shortest paths of the node pairs, to preserve the structural features of nodes and feed them into the vanilla Transformer to learn the representations of nodes. It is hard for such predefined rules to extract informative graph structural features for arbitrary graphs whose topology structure varies greatly, limiting the learning capacity of the models. To this end, we propose an adaptive graph Transformer, termed Multi-Neighborhood Attention based Graph Transformer (MNA-GT), which captures the graph structural information for each node from the multi-neighborhood attention mechanism adaptively. By defining the input to perform scaled-dot product as an attention kernel, MNA-GT constructs multiple attention kernels based on different hops of neighborhoods such that each attention kernel can capture specific graph structural information of the corresponding neighborhood for each node pair. In this way, MNA-GT can preserve the graph structural information efficiently by incorporating node representations learned by different attention kernels. MNA-GT further employs an attention layer to learn the importance of different attention kernels to enable the model to adaptively capture the graph structural information for different nodes. Extensive experiments are conducted on a variety of graph benchmarks, and the empirical results show that MNA-GT outperforms many strong baselines.