 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Estimation in Structured Factor Models with Applications to Overlapping Clustering
Paper and Code
Mar 22, 2018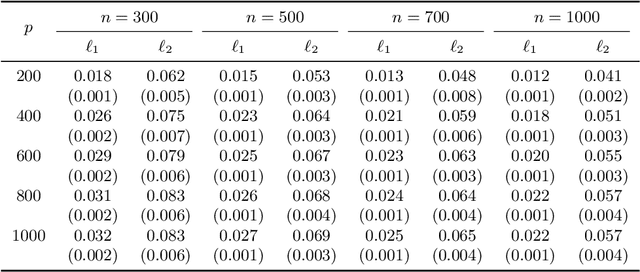
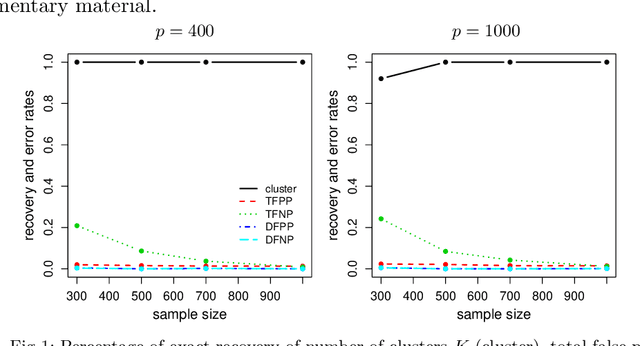
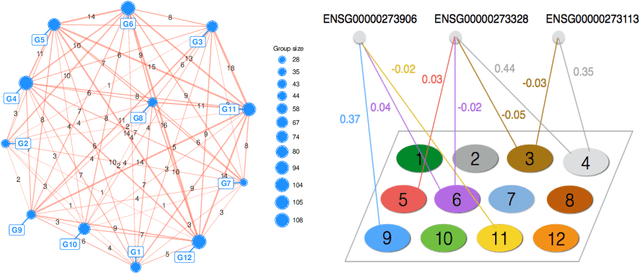
This work introduces a novel estimation method, called LOVE, of the entries and structure of a loading matrix A in a sparse latent factor model X = AZ + E, for an observable random vector X in Rp, with correlated unobservable factors Z \in RK, with K unknown, and independent noise E. Each row of A is scaled and sparse. In order to identify the loading matrix A, we require the existence of pure variables, which are components of X that are associated, via A, with one and only one latent factor. Despite the fact that the number of factors K, the number of the pure variables, and their location are all unknown, we only require a mild condition on the covariance matrix of Z, and a minimum of only two pure variables per latent factor to show that A is uniquely defined, up to signed permutations. Our proofs for model identifiability are constructive, and lead to our novel estimation method of the number of factors and of the set of pure variables, from a sample of size n of observations on X. This is the first step of our LOVE algorithm, which is optimization-free, and has low computational complexity of order p2. The second step of LOVE is an easily implementable linear program that estimates A. We prove that the resulting estimator is minimax rate optimal up to logarithmic factors in p. The model structure is motivated by the problem of overlapping variable clustering, ubiquitous in data science. We define the population level clusters as groups of those components of X that are associated, via the sparse matrix A, with the same unobservable latent factor, and multi-factor association is allowed. Clusters are respectively anchored by the pure variables, and form overlapping sub-groups of the p-dimensional random vector X. The Latent model approach to OVErlapping clustering is reflected in the name of our algorithm, LOVE.