 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting to the Long Tail: A Meta-Analysis of Transfer Learning Research for Language Understanding Tasks
Paper and Code
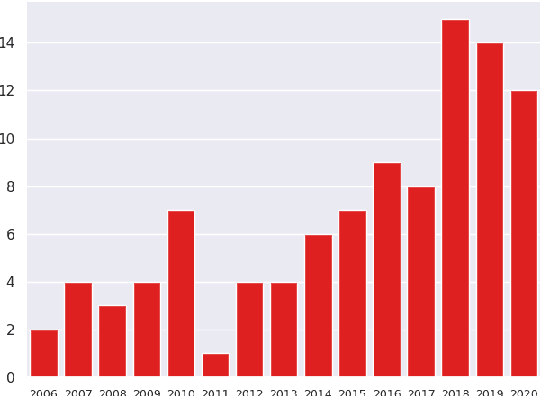

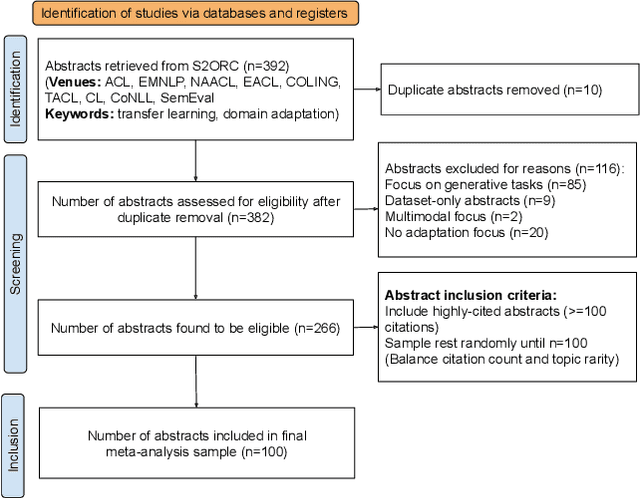
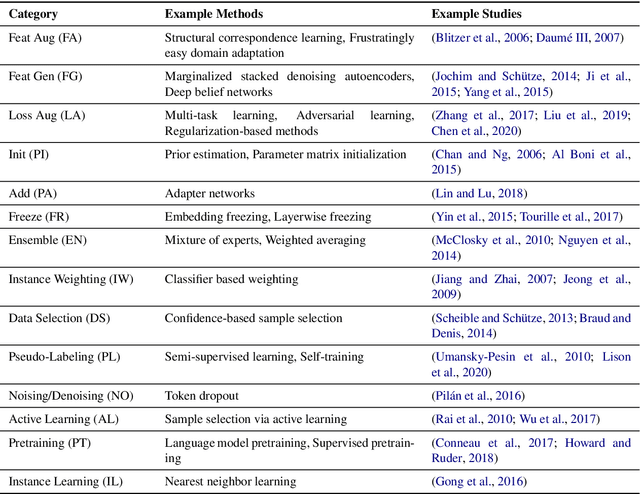
Natural language understanding (NLU) has made massive progress driven by large benchmarks, paired with research on transfer learning to broaden its impact. Benchmarks are dominated by a small set of frequent phenomena, leaving a long tail of infrequent phenomena underrepresented. In this work, we reflect on the question: have transfer learning methods sufficiently addressed performance of benchmark-trained models on the long tail? Since benchmarks do not list included/excluded phenomena, we conceptualize the long tail using macro-level dimensions such as underrepresented genres, topics, etc. We assess trends in transfer learning research through a qualitative meta-analysis of 100 representative papers on transfer learning for NLU. Our analysis asks three questions: (i) Which long tail dimensions do transfer learning studies target? (ii) Which properties help adaptation methods improve performance on the long tail? (iii) Which methodological gaps have greatest negative impact on long tail performance? Our answers to these questions highlight major avenues for future research in transfer learning for the long tail. Lastly, we present a case study comparing the performance of various adaptation methods on clinical narratives to show how systematically conducted meta-experiments can provide insights that enable us to make progress along these future avenues.