 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting General Disentanglement-Based Speaker Anonymization for Enhanced Emotion Preservation
Paper and Code
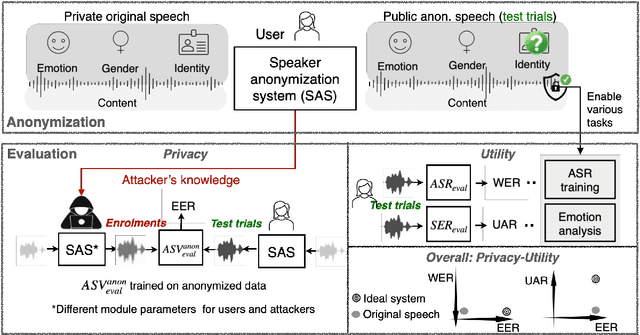
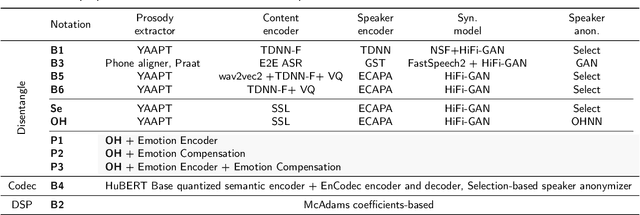
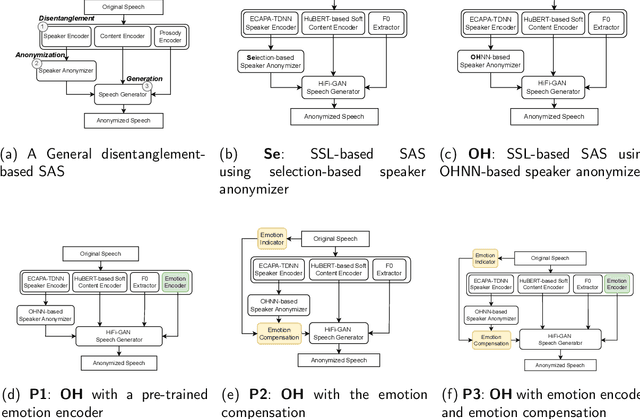
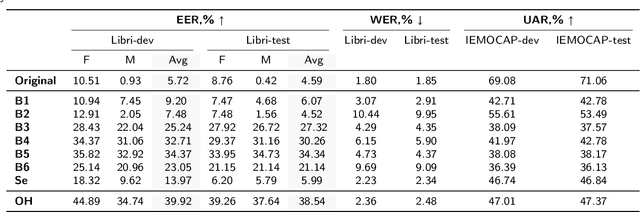
A general disentanglement-based speaker anonymization system typically separates speech into content, speaker, and prosody features using individual encoders. This paper explores how to adapt such a system when a new speech attribute, for example, emotion, needs to be preserved to a greater extent. While existing systems are good at anonymizing speaker embeddings, they are not designed to preserve emotion. Two strategies for this are examined. First, we show that integrating emotion embeddings from a pre-trained emotion encoder can help preserve emotional cues, even though this approach slightly compromises privacy protection. Alternatively, we propose an emotion compensation strategy as a post-processing step applied to anonymized speaker embeddings. This conceals the original speaker's identity and reintroduces the emotional traits lost during speaker embedding anonymization. Specifically, we model the emotion attribute using support vector machines to learn separate boundaries for each emotion. During inference, the original speaker embedding is processed in two ways: one, by an emotion indicator to predict emotion and select the emotion-matched SVM accurately; and two, by a speaker anonymizer to conceal speaker characteristics. The anonymized speaker embedding is then modified along the corresponding SVM boundary towards an enhanced emotional direction to save the emotional cues. The proposed strategies are also expected to be useful for adapting a general disentanglement-based speaker anonymization system to preserve other target paralinguistic attributes, with potential for a range of downstream tasks.