 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Event Extractors to Medical Data: Bridging the Covariate Shift
Paper and Code
Aug 21, 2020
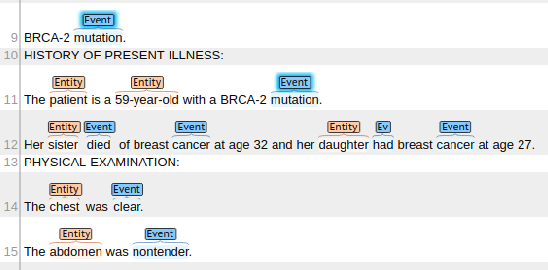
We tackle the task of adapting event extractors to new domains without labeled data, by aligning the marginal distributions of source and target domains. As a testbed, we create two new event extraction datasets using English texts from two medical domains: (i) clinical notes, and (ii) doctor-patient conversations. We test the efficacy of three marginal alignment techniques: (i) adversarial domain adaptation (ADA), (ii) domain adaptive fine-tuning (DAFT), and (iii) a novel instance weighting technique based on language model likelihood scores (LIW). LIW and DAFT improve over a no-transfer BERT baseline on both domains, but ADA only improves on clinical notes. Deeper analysis of performance under different types of shifts (e.g., lexical shift, semantic shift) reveals interesting variations among models. Our best-performing models reach F1 scores of 70.0 and 72.9 on notes and conversations respectively, using no labeled data from target domains.