Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation to the Range in $K$-Armed Bandits
Paper and Code
Jun 05, 2020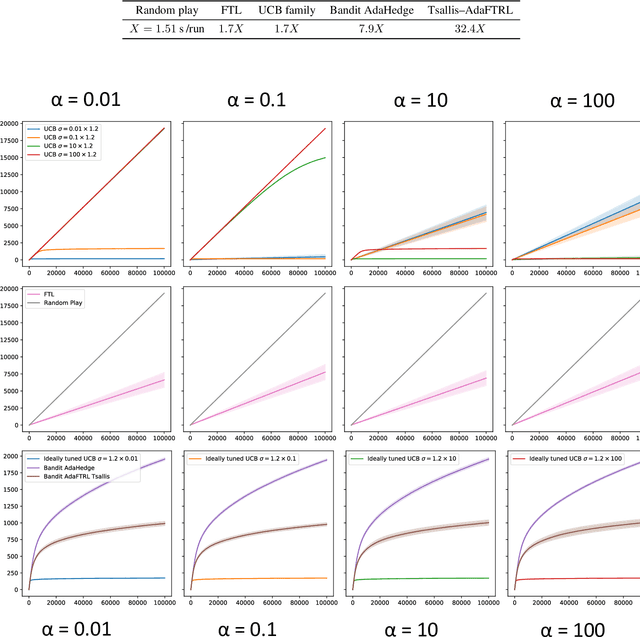
We consider stochastic bandit problems with $K$ arms, each associated with a bounded distribution supported on the range $[m,M]$. We do not assume that the range $[m,M]$ is known and show that there is a cost for learning this range. Indeed, a new trade-off between distribution-dependent and distribution-free regret bounds arises, which, for instance, prevents from simultaneously achieving the typical $\ln T$ and $\sqrt{T}$ bounds. For instance, a $\sqrt{T}$ distribution-free regret bound may only be achieved if the distribution-dependent regret bounds are at least of order $\sqrt{T}$. We exhibit a strategy achieving the rates for regret indicated by the new trade-off.
View paper on