Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation Algorithm and Theory Based on Generalized Discrepancy
Paper and Code
Feb 21, 2015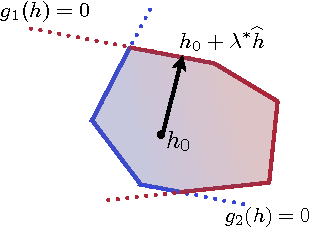
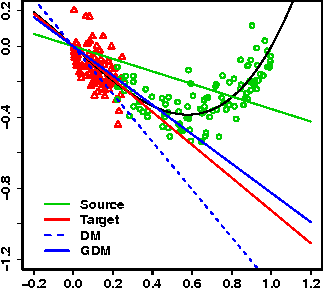
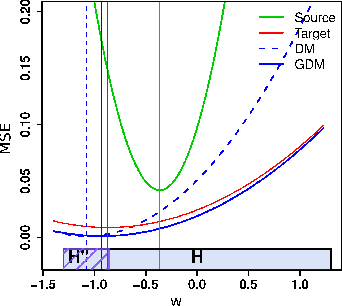
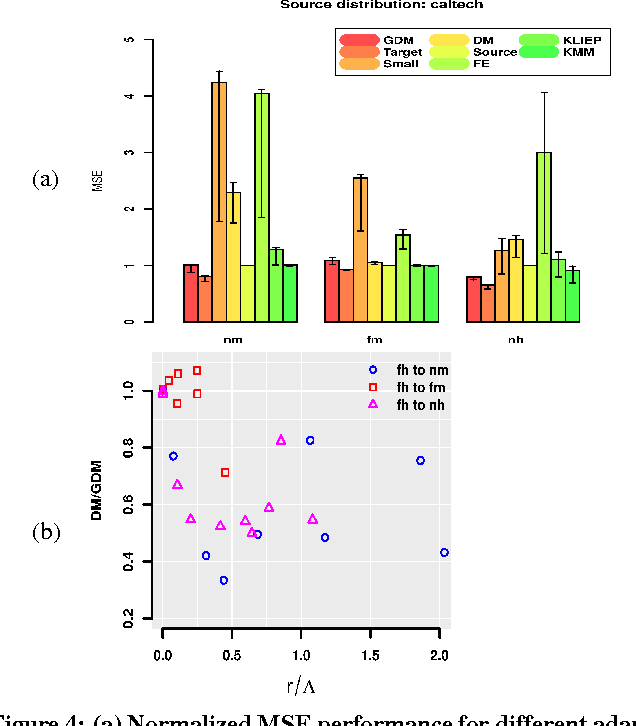
We present a new algorithm for domain adaptation improving upon a discrepancy minimization algorithm previously shown to outperform a number of algorithms for this task. Unlike many previous algorithms for domain adaptation, our algorithm does not consist of a fixed reweighting of the losses over the training sample. We show that our algorithm benefits from a solid theoretical foundation and more favorable learning bounds than discrepancy minimization. We present a detailed description of our algorithm and give several efficient solutions for solving its optimization problem. We also report the results of several experiments showing that it outperforms discrepancy minimization.
View paper on