 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAMT: A Stochastic Optimization with Trend Correction Scheme
Paper and Code

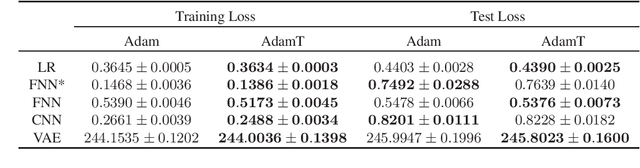

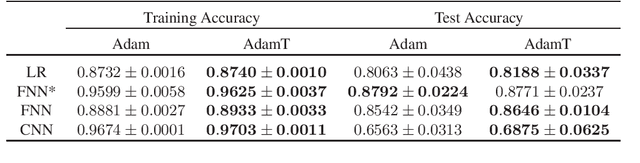
Adam-type optimizers, as a class of adaptive moment estimation methods with the exponential moving average scheme, have been successfully used in many applications of deep learning. Such methods are appealing for capability on large-scale sparse datasets with high computational efficiency. In this paper, we present a new framework for adapting Adam-type methods, namely AdamT. Instead of applying a simple exponential weighted average, AdamT also includes the trend information when updating the parameters with the adaptive step size and gradients. The additional terms promise an efficient movement on the complex cost surface, and thus the loss would converge more rapidly. We show empirically the importance of adding the trend component, where AdamT outperforms the vanilla Adam method constantly with state-of-the-art models on several classical real-world datasets.