 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam through a Second-Order Lens
Paper and Code
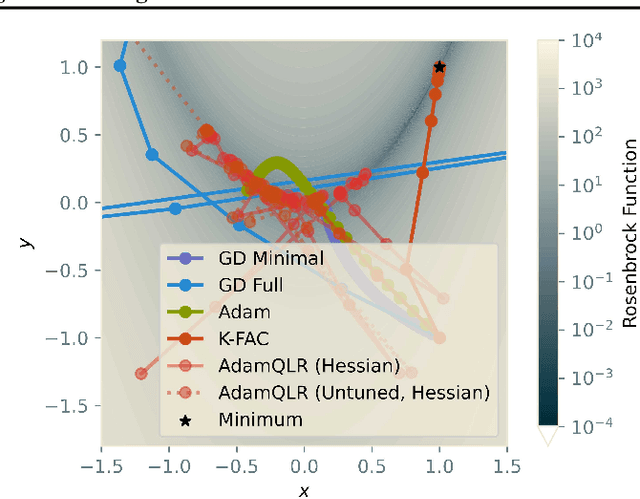

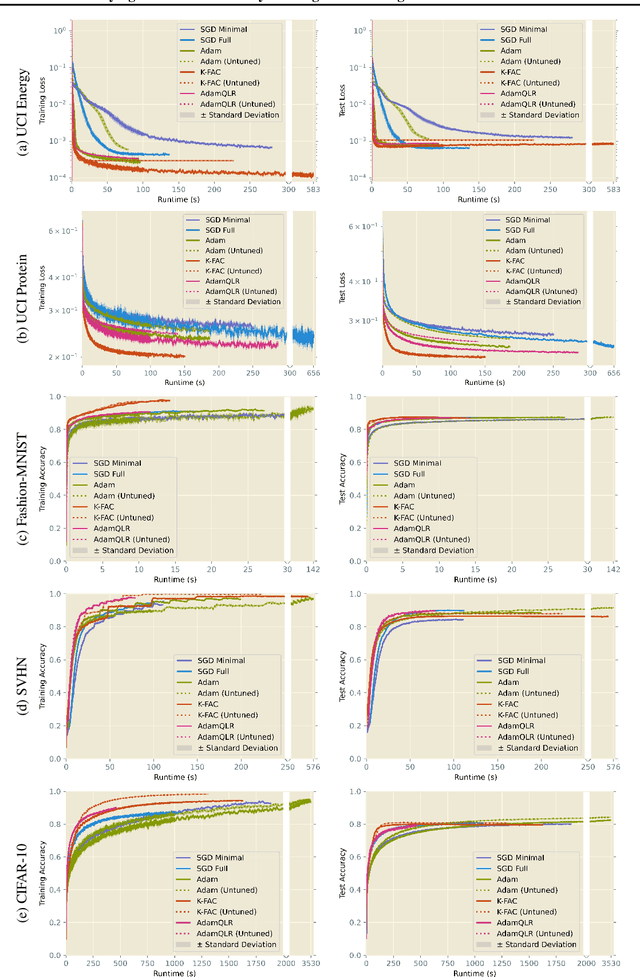

Research into optimisation for deep learning is characterised by a tension between the computational efficiency of first-order, gradient-based methods (such as SGD and Adam) and the theoretical efficiency of second-order, curvature-based methods (such as quasi-Newton methods and K-FAC). We seek to combine the benefits of both approaches into a single computationally-efficient algorithm. Noting that second-order methods often depend on stabilising heuristics (such as Levenberg-Marquardt damping), we propose AdamQLR: an optimiser combining damping and learning rate selection techniques from K-FAC (Martens and Grosse, 2015) with the update directions proposed by Adam, inspired by considering Adam through a second-order lens. We evaluate AdamQLR on a range of regression and classification tasks at various scales, achieving competitive generalisation performance vs runtime.