 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaGrad stepsizes: Sharp convergence over nonconvex landscapes, from any initialization
Paper and Code
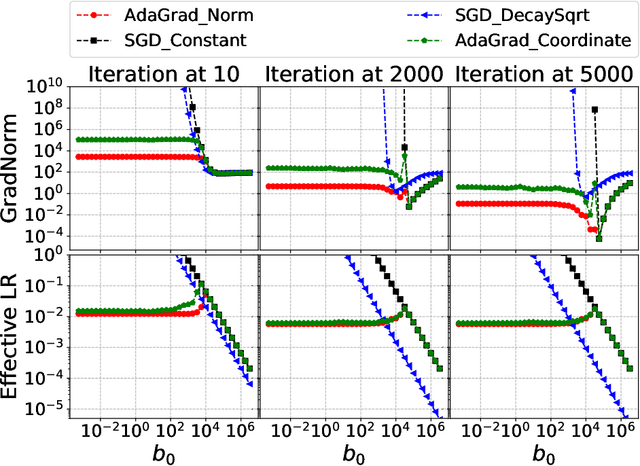

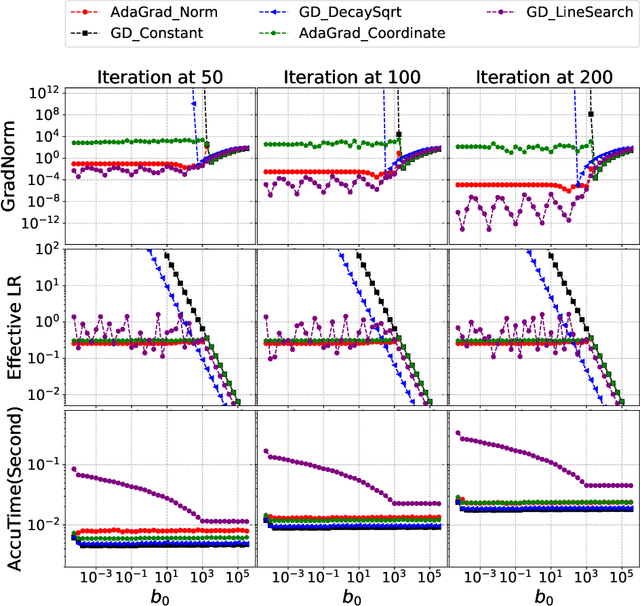

Adaptive gradient methods such as AdaGrad and its variants update the stepsize in stochastic gradient descent on the fly according to the gradients received along the way; such methods have gained widespread use in large-scale optimization for their ability to converge robustly, without the need to fine tune parameters such as the stepsize schedule. Yet, the theoretical guarantees to date for AdaGrad are for online and convex optimization, which is quite different from the offline and nonconvex setting where adaptive gradient methods shine in practice. We bridge this gap by providing strong theoretical guarantees in batch and stochastic setting, for the convergence of AdaGrad over smooth, nonconvex landscapes, from any initialization of the stepsize, without knowledge of Lipschitz constant of the gradient. We show in the stochastic setting that AdaGrad converges to a stationary point at the optimal $O(1/\sqrt{N})$ rate (up to a $\log(N)$ factor), and in the batch setting, at the optimal $O(1/N)$ rate. Moreover, in both settings, the constant in the rate matches the constant obtained as if the variance of the gradient noise and Lipschitz constant of the gradient were known in advance and used to tune the stepsize, up to a logarithmic factor of the mismatch between the optimal stepsize and the stepsize used to initialize AdaGrad. In particular, our results imply that AdaGrad is robust to both the unknown Lipschitz constant and level of stochastic noise on the gradient, in a near-optimal sense. When there is noise, AdaGrad converges at the rate of $O(1/\sqrt{N})$ with well-tuned stepsize, and when there is not noise, the same algorithm converges at the rate of $O(1/N)$ like well-tuned batch gradient descent.