 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCap: Adaptive Capacity control for Feed-Forward Neural Networks
Paper and Code
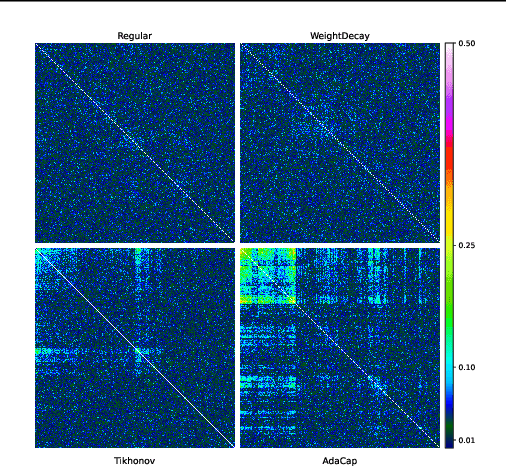
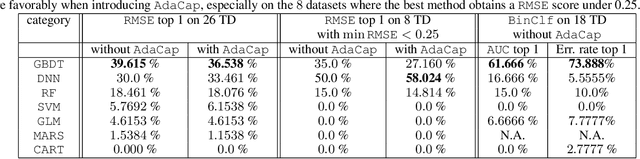
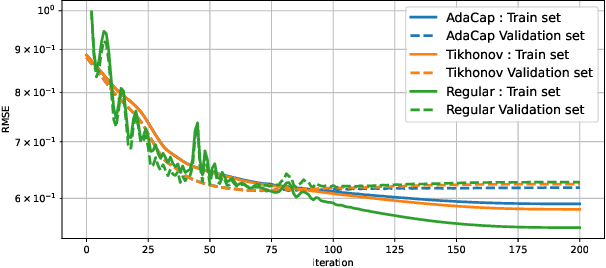
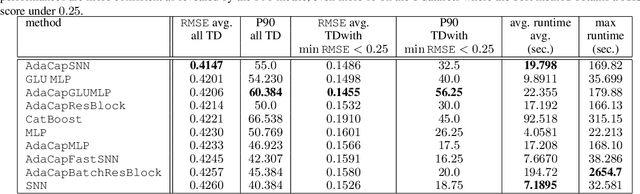
The capacity of a ML model refers to the range of functions this model can approximate. It impacts both the complexity of the patterns a model can learn but also memorization, the ability of a model to fit arbitrary labels. We propose Adaptive Capacity (AdaCap), a training scheme for Feed-Forward Neural Networks (FFNN). AdaCap optimizes the capacity of FFNN so it can capture the high-level abstract representations underlying the problem at hand without memorizing the training dataset. AdaCap is the combination of two novel ingredients, the Muddling labels for Regularization (MLR) loss and the Tikhonov operator training scheme. The MLR loss leverages randomly generated labels to quantify the propensity of a model to memorize. We prove that the MLR loss is an accurate in-sample estimator for out-of-sample generalization performance and that it can be used to perform Hyper-Parameter Optimization provided a Signal-to-Noise Ratio condition is met. The Tikhonov operator training scheme modulates the capacity of a FFNN in an adaptive, differentiable and data-dependent manner. We assess the effectiveness of AdaCap in a setting where DNN are typically prone to memorization, small tabular datasets, and benchmark its performance against popular machine learning methods.