 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Testing: An Efficient and Robust Framework for Estimating Accuracy
Paper and Code
Jul 02, 2018

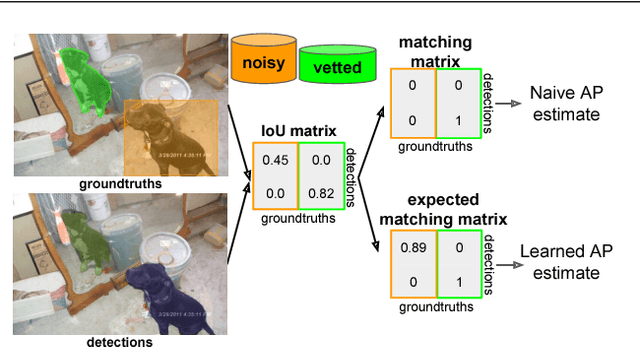

Much recent work on visual recognition aims to scale up learning to massive, noisily-annotated datasets. We address the problem of scaling- up the evaluation of such models to large-scale datasets with noisy labels. Current protocols for doing so require a human user to either vet (re-annotate) a small fraction of the test set and ignore the rest, or else correct errors in annotation as they are found through manual inspection of results. In this work, we re-formulate the problem as one of active testing, and examine strategies for efficiently querying a user so as to obtain an accu- rate performance estimate with minimal vetting. We demonstrate the effectiveness of our proposed active testing framework on estimating two performance metrics, Precision@K and mean Average Precision, for two popular computer vision tasks, multi-label classification and instance segmentation. We further show that our approach is able to save significant human annotation effort and is more robust than alternative evaluation protocols.