 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Sampling for Linear Regression Beyond the $\ell_2$ Norm
Paper and Code
Nov 09, 2021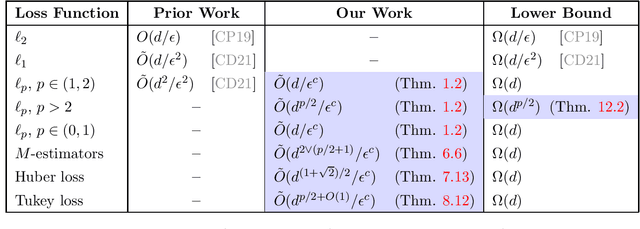
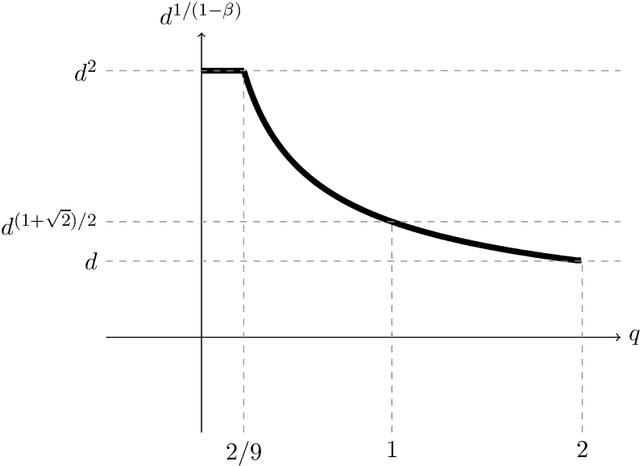
We study active sampling algorithms for linear regression, which aim to query only a small number of entries of a target vector $b\in\mathbb{R}^n$ and output a near minimizer to $\min_{x\in\mathbb{R}^d}\|Ax-b\|$, where $A\in\mathbb{R}^{n \times d}$ is a design matrix and $\|\cdot\|$ is some loss function. For $\ell_p$ norm regression for any $0<p<\infty$, we give an algorithm based on Lewis weight sampling that outputs a $(1+\epsilon)$ approximate solution using just $\tilde{O}(d^{\max(1,{p/2})}/\mathrm{poly}(\epsilon))$ queries to $b$. We show that this dependence on $d$ is optimal, up to logarithmic factors. Our result resolves a recent open question of Chen and Derezi\'{n}ski, who gave near optimal bounds for the $\ell_1$ norm, and suboptimal bounds for $\ell_p$ regression with $p\in(1,2)$. We also provide the first total sensitivity upper bound of $O(d^{\max\{1,p/2\}}\log^2 n)$ for loss functions with at most degree $p$ polynomial growth. This improves a recent result of Tukan, Maalouf, and Feldman. By combining this with our techniques for the $\ell_p$ regression result, we obtain an active regression algorithm making $\tilde O(d^{1+\max\{1,p/2\}}/\mathrm{poly}(\epsilon))$ queries, answering another open question of Chen and Derezi\'{n}ski. For the important special case of the Huber loss, we further improve our bound to an active sample complexity of $\tilde O(d^{(1+\sqrt2)/2}/\epsilon^c)$ and a non-active sample complexity of $\tilde O(d^{4-2\sqrt 2}/\epsilon^c)$, improving a previous $d^4$ bound for Huber regression due to Clarkson and Woodruff. Our sensitivity bounds have further implications, improving a variety of previous results using sensitivity sampling, including Orlicz norm subspace embeddings and robust subspace approximation. Finally, our active sampling results give the first sublinear time algorithms for Kronecker product regression under every $\ell_p$ norm.