 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning Improves Performance on Symbolic RegressionTasks in StackGP
Paper and Code
Feb 09, 2022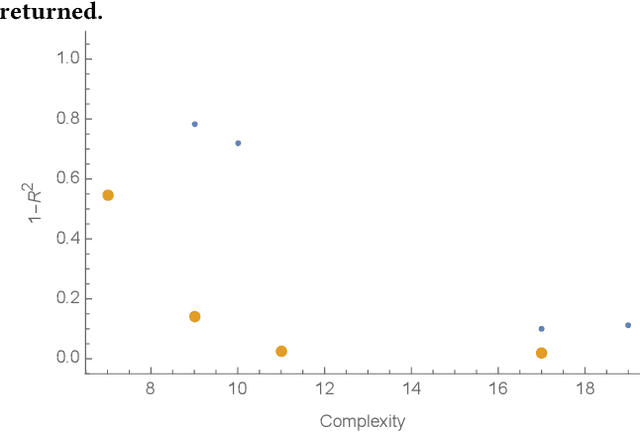
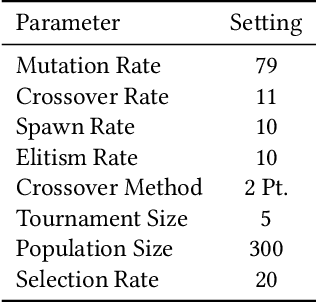

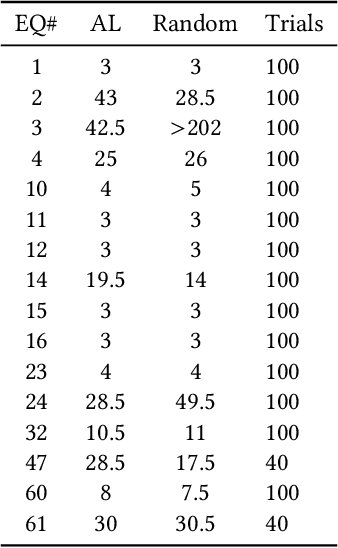
In this paper we introduce an active learning method for symbolic regression using StackGP. The approach begins with a small number of data points for StackGP to model. To improve the model the system incrementally adds a data point such that the new point maximizes prediction uncertainty as measured by the model ensemble. Symbolic regression is re-run with the larger data set. This cycle continues until the system satisfies a termination criterion. We use the Feynman AI benchmark set of equations to examine the ability of our method to find appropriate models using fewer data points. The approach was found to successfully rediscover 72 of the 100 Feynman equations using as few data points as possible, and without use of domain expertise or data translation.