 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Vision-Language Models
Paper and Code
Oct 29, 2024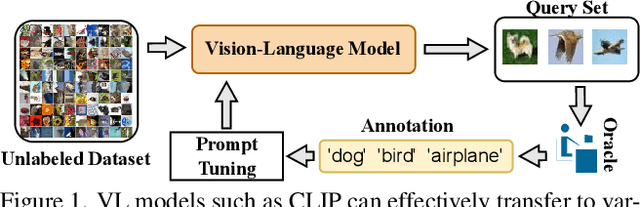
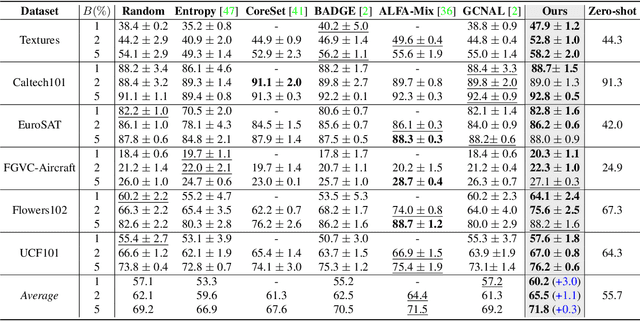
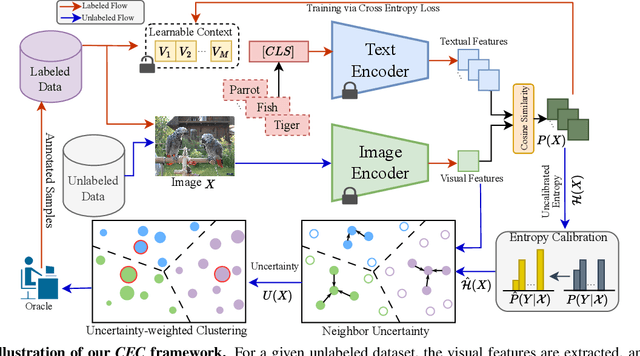
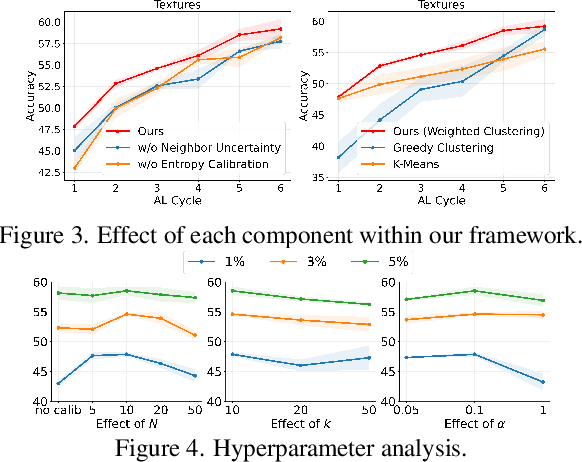
Pre-trained vision-language models (VLMs) like CLIP have demonstrated impressive zero-shot performance on a wide range of downstream computer vision tasks. However, there still exists a considerable performance gap between these models and a supervised deep model trained on a downstream dataset. To bridge this gap, we propose a novel active learning (AL) framework that enhances the zero-shot classification performance of VLMs by selecting only a few informative samples from the unlabeled data for annotation during training. To achieve this, our approach first calibrates the predicted entropy of VLMs and then utilizes a combination of self-uncertainty and neighbor-aware uncertainty to calculate a reliable uncertainty measure for active sample selection. Our extensive experiments show that the proposed approach outperforms existing AL approaches on several image classification datasets, and significantly enhances the zero-shot performance of VLMs.